As described in this article, PASS “is ceasing all regular operations, effective January 15, 2021”. The 2020 has been one of the worst year ever for many companies and that is true also for the one behind the Professional Association of SQL Server.
That being said, our beloved SQL Saturdays (Parma, Pordenone, Milan, Turin, Ancona, Verona, etc.) will not be held anymore. To be honest, SQLSaturdays have been great from many perspectives:
Community aggregation
Offline networking
Content sharing
People relationship
So what? Are we losing these opportunities forever?
Well, the #sqlfamily is great and I’m proud to be part of it. But, the question is, how can we keep the value of the SQLSaturdays? We’ll start from scratch with the spirit of one of the strongest tech community ever known.
A migration, no matter what is the involved set of technologies, is one of the hardest tasks to deal with. Not just for IT. However, working with the culture of many companies, I’ve got confirmation that the tool should be considered at the end of the migration process. Indeed, after setting up the ceremonies, involving the patterns of the team working, switching the methodologies from legacy to lean/iterative, it comes finally to understand how to choose from the available tools (part of the “enterprise awareness”) and including a set of new tools, optionally. The goal is to get all the stuff which fit the real scenario.
This post is a quick step by step guide to migrate work items from Jira cloud to Azure DevOps Services. I’m going to describe the last step of one of my customers’ migration.
Getting started
Before going in-depth with technical details, I would like to share some tips. As we have already said, the migrations are complex tasks. Mandatory requirements should be a strong knowledge in terms of business and team management, enterprise awareness and years of experience on different real scenarios.
We must avoid any decision if our ideas and targets are not clear. Indeed, another important requirement is to understand in depth the workflows you will work on, both the legacy one and the new one you’re figuring out. Some of the question we should ask ourselves are:
Do we require these steps? And what about these work items?
Is this state workflow good for us? Should we change it? How?
Do we require to preserve relationships and items’ history?
Can we keep something which is working very well now? If so, what tools we’re thinking about?
The software selection
The software selection has ended up on a tool made by Solidify (Thanks to the experienced members of our getlatestversion.eu community). Anyways, you can find more of them. For example:
When exporting from Jira, the CLI implemented by Solidify connects to the Jira server (cloud by default and on-premises when configured), executes a JQL query for extracting the Jira so-called “Issues”, evaluates and applies the mapping between users, work items, relationships and states, and exports a JSON file for each item.
When importing to Azure DevOps, the CLI imports the output JSON files using the same mapping configured into the configuration file in the exporting phase.
Why this tool? Because it has a couple of simple command lines and it consumes a JSON configuration which is clear. Additionally, it has many default behaviors, like the built-in configuration for SCRUM, agile and basic process templates, which allows us to forget about the complexity of both the source and target software.
Executing the tool
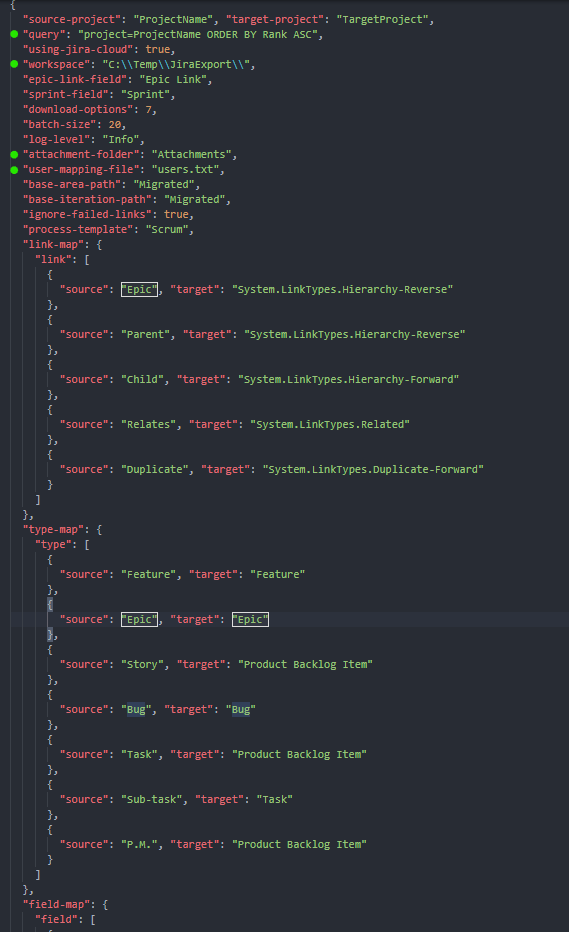
The scenario I’ve dealt with, Jira side, has been configured with many states, also with the same meaning (due to the legacy setup and different team’s approach) and with custom workflows/links. On the other hand, Azure DevOps side, I’ve created a customized Scrum template, with just two new work item types, which should support some of the customized source behaviors, and a couple of new states.
So the tool has been configured as depicted in the following JSON (just a subset of maps):
Just that. Notice that we can configure project names, the JQL query for gathering issues, working folder names and the file for the user mappings.
create a folder called C:/Temp/JiraExport (you can configure this editing the JSON config file)
create a file called “users.txt” within that folder and put into it a list of jirauser@domain.ext=AzDOs@domain.ext records
please note that the Jira user can be represented without the domain, depending on its configuration
copy the JSON configuration file (based on he template we’re going to apply when importing) into the JiraExport folder
modify the file in the maps section: link-map, type-map, field-map, and so on.
get the credentials (as admin) and the Jira server URL
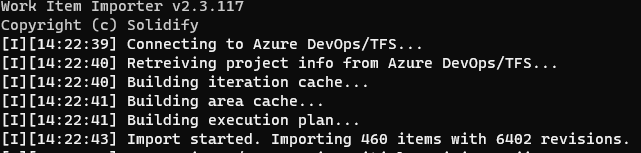
make your command line, which should look like the following: jira-export -u username@domain.ext -p userPwd --url https://jiraurl.ext --config config-scrum.json --force
run the command and look for the JSON files into the JiraExport folder
look for any warning/error like the following and correct them (this will help you to import without any breaking change)
The missing mapping between Wip status and Story item
How to import to Azure DevOps
It’s time to execute the second command line, wi-import. As we can see, we have to get a personal access token (PAT) from Azure DevOps, as described in the documentation, with the full access.
Coming back to the configuration, we should pay attention to base-area-path and base-iteration-path. With these, we can choose the target of our migration, in terms of area and iteration. This means that we can manage our items after the import has been completed. With a query, for example, we can remove everything and start over with the migration. Cool.
The command should like the following:
wi-import --token PAT --url https://dev.azure.com/org --config config-scrum.json --force
After ten minutes we’ve got new areas and iterations:
The Azure DevOps hierarchy of items (except for the Features, which I’ve not mapped) has been preserved and also the history of any item:
Conclusions
In a couple of days, we’ve migrated everything related to work items from Jira to Azure DevOps. Most of the time should be invested in configuring the JSON mappings and, for sure, to check for the errors caught during exporting items. Finally, after importing into AzDOs, you can start over and over, removing all the items under the pre-configured area/iteration, until everything looks good.
The task of creating tables, storing data in records look quite easy to SQL Server users. But if the data is being deleted by mistake or because of some other hardware or software issues, then the situation becomes complex. Recovery of deleted data is not a child’s play. So, considering this issue we have come up with this write-up which will help you to know various methods to answer your query how to recover deleted data from SQL server table by transaction logs? Let’s begin with a detailed discussion on the same.
Techniques to Rely On For Recovering The Deleted Data From Server:
1. Manual Method: – Using LSNs (Log Sequence Numbers), but it works only if the time of deletion is known to the user. 2. Automated Solution: – Simple yet secure and reliable solution for recovering deleted data from the server by using SysTools SQL MDF Database Recovery.
Know-How to Recover Deleted Data From SQL Server Table by Transaction Logs
Deleted Records’ Recovery Using SQL Server LSN:- In SQL Server transaction logs, the LSN(Log Sequence Number) is nothing but unique identifiers assigned to each record. Here we can restore the deleted rows of SQL tables if the time when the record was deleted is known.
User has to be ensured that the Full Recovery Model or Logged Recovery Model were created when the data was actually deleted for starting the recovery process. This is the prerequisite for the successful recovery of the deleted records.
The steps are described below to recover the deleted data from SQL Server 2016, 2015, 2014, 2012, 2008 and 2005.
Step 1: Fire the following query to know the total number of records in a table where from th record is being deleted.
Select * From Table_Name Step 2: Next, run the procedure to take log back using the below-mentioned query: USE NameOfTheDatabase GO BACKUP LOG (NameOfTheDatabase) TO DISK = N’D:\ NameOfTheDatabase\RDDTrLog.trn’ WITH NOFORMAT, NOINIT, NAME = N’NameOfTheDatabase-Transaction Log Backup’, SKIP, NOREWIND, NOUNLOAD, STATS = 10 GO Step 3: Information has to be collected from the SQL Server table about the deleted records for data recovery. This query will retrieve Transaction ID of the deleted records. USE NameOfTheDatabase GO Select [Current LSN] LSN], [Transaction ID], Operation, Context, AllocUnitName FROM fn_dblog(NULL, NULL) WHERE Operation = ‘LOP_DELETE_ROWS’
Step 4: Execute the query given below to know at what time exactly the records get deleted. USE NameOfTheDatabase GO SELECT [Current LSN], Operation, [Transaction ID], [Begin Time], [Transaction Name], [Transaction SID] FROM fn_dblog(NULL, NULL) WHERE [Transaction ID] = ‘000:000001f3′ AND [Operation] = ‘LOP_BEGIN_XACT’
Ongoing LSN you will be able to find now query. Step 5: Restore process has to be run to restore the deleted data from the SQL Server Table. Recover Deleted D USE NameOfTheDatabase GO RESTORE DATABASE NameOfTheDatabase _COPY FROM DISK = ‘D:\ NameOfTheDatabase \RDDFull.bak’ WITH MOVE ‘NameOfTheDatabase’ TO ‘D:\RecoverDB\ NameOfTheDatabase.mdf’, MOVE ‘NameOfTheDatabase _log’ TO ‘D:\RecoverDB\ NameOfTheDatabase_log.ldf’, REPLACE, NORECOVERY; GO Step 6: Now is the time to verify if deleted records are recovered or not.
Efficient Way to Recover Deleted Records From SQL Server 2017 / 2016 / 2014
If you failed to recover deleted data from SQL server table by transaction logs then you can take the helpSQL Database Recovery software. This software provides you the option to recover deleted records from SQL server table. Also by using this software, the user can preview accidentally deleted SQL tables records in red color. The user can easily recover database objects such as tables, functions, stored procedure. Moreover, This application is compatible with SQL server 2017 and its below version.
Follow The Steps to Recover Deleted Records From SQL Server Table
1. Download and Install the software on your machine.
2. Click on Add file button and add the MDF file in the software.
3. Now choose the Scan option and select the SQL server version.
4. Check the option preview deleted SQL database records in red color.
5. Preview the SQL server database items. The software will preview the deleted SQL table records in red color.
6. And click on Export button to Export the SQL database.
7. Now in database authentication choose the server name and the authentication mode.
8. Now choose the destination database
9. Check the Database items you want to export.
10. Choose the option from with onlyschema and schema and data.
11. Mark the option Export deleted records and finally click on Export button.
Final Words
In this article, we have discussed how to recover deleted data from the SQL server table by transaction logs. The manual solution is quite lengthy and difficult to perform. It requires strong technical knowledge. So it is better to take the help of SQL database recovery tool to recover deleted records easily.
While writing a sample random function in using T-SQL Server, I have remembered, why not write a job title generator for T-SQL domain only. You might have seen so called bulls**t job title generator and similar, but this one is T-SQL SQL server specific.
So, why not come up with random, yet funny T-SQL job titles. And making it, I have to tell you, it was fun. And I was simply hitting that F5 button in SSMS, to get new job title generated and laugh out loud.
Following this laughter, I have created the following website:
that encapsulated the T-SQL code explained in this blog. You can either copy/paste the T-SQL code and run it in your SSMS or visit the T-sql job title generator web site.
The code
Staging some data, I have created just some random words, consisting of three parts. One is just IT slang/jargon…
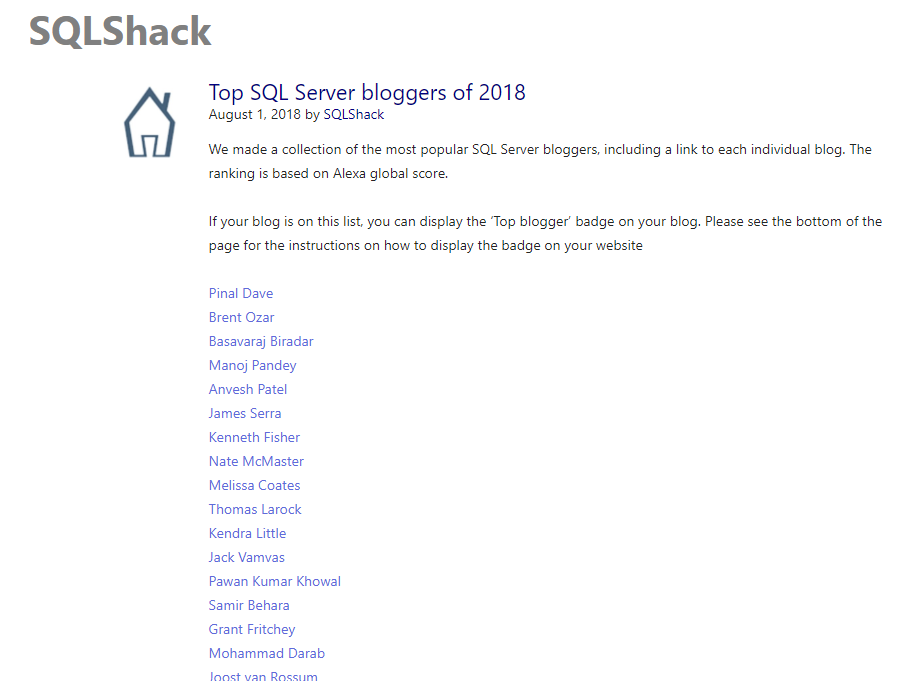
The list of top SQL Server bloggers is absolutely worth checking for entry-level learning, for troubleshooting and for advanced topics. There are also many other top list of bloggers – PowerShell and others.
Based on ALEXA ranking the list for sorted by relevance. My blog also managed to get on the list, humbled and honoured to be recognised for my community work. Congrats to all SQL fellows and SQL family and all the SQL lovers. Thank you also to SQLShack community for doing this.
Siamo quasi giunti alla fine di questa edizione di Agile@School presso l’I.I.S.S. Gadda di Fornovo, Parma. Nella puntata precedente abbiamo visto i diversi team presentare i loro progetti, venendo a conoscenza degli strumenti utili alla collaborazione e alla gestione efficiente delle attività tra cui Slack, Trello ed il concetto di retrospettiva mediante l’utilizzo di una starfish. A tal proposito è stato chiesto di presentarne una fatta da loro contenente tutti i punti, suddivisi nelle varie aree, che hanno raccolto nel corso dell’ultima settimana. Siete pronti? Cominciamo!
Retrospettive
Nel presentare le retrospettive, i ragazzi hanno mostrato ancora una volta una vasta creatività nella presentazione, andando ben oltre a quanto richiesto dal punto di vista visivo, giocando anche con il termine stesso di starfish per creare un risultato di impatto agli occhi della classe.
A presentazioni concluse, è emerso un ottimo spirito critico dei ragazzi nei confronti delle attività che hanno svolto questa settimana in cui hanno mostrato di aver utilizzato gli strumenti da loro consigliati in precedenza e, ancora più importante, di aver gestito positivamente le differenze e le diversità all’interno del team andando in generale d’accordo l’uno con l’altro risolvendo problemi di natura tecnica mediante una stretta collaborazione. L’unica nota “negativa” è data dal fatto che tutti i gruppi si sono concentrati troppo sullo storytelling e sull’aspetto grafico rispetto ai contenuti e alla loro suddivisione, portando a non soddisfare a pieno le nostre richieste. In ogni caso però si trattava della loro prima retrospettiva, pertanto ci è sembrato giusto chiudere un occhio su quest’ultimo aspetto apprezzando il loro impegno.
Stato avanzamento lavori
Finita la retrospettiva, abbiamo chiesto ai ragazzi come stesse procedendo il loro lavoro e, con nostra sorpresa, è emerso che tutti i gruppi hanno già cominciato a sviluppare il software e a cablare i loro circuiti, arrivando a completare in alcuni casi più della metà delle attività da loro stimate in precedenza. Non è stato necessario fornirgli consulenza tecnica in quanto la scuola si è prestata ad aiutarli e sostenerli in questo percorso sia dal punto di vista elettronico, acquistando il materiale necessario e spiegando il corretto processo di cablaggio, sia dal punto di vista informatico, risolvendo eventuali dubbi di programmazion ed interfacciamento con i dispositivi.
Conclusione
Non possiamo che essere contenti quindi del lavoro che hanno svolto, avendo l’ennesima conferma del fatto che agire sull’organizzazione e sulle metodologie che stanno dietro al lavoro pratico porta ad ottenere risultati tangibili e duraturi, anche nei confronti di chi come loro non ha mai avuto modo di sperimentare la cosa.
Come compito per l’ultimo incontro, che avverrà venerdì prossimo, abbiamo chiesto ai ragazzi di portare una presentazione del loro prodotto con tanto di codice e circuiti funzionanti. Nessuna direttiva sugli strumenti da seguire, nessuno schema di esposizione: gli è stato permesso di sbizzarirsi con la creatività, alimentando un pò di sana competizione. Come finirà? Per scoprirlo, rimanete sintonizzati in attesa del prossimo post!
Per oggi quindi è tutto, ci vediamo alla prossima puntata!
Settimo appuntamento presso la scuola rodigina IIS Viola/Marchesini per il progetto Agile@School nella giornata di ieri 24 gennaio 2018. Si è giunti alla parte finale dove cerchiamo di mettere insieme tutte le parti finora studiate. Ci siamo dati come obiettivo quello di realizzare una semplice app per l’accesso a Twitter mettendo in gioco le conoscenze apprese.
As a recurring project, Agile@School is started again on February, with a new set of projects and ideas. Gabriele will help me again, but it will be a very difficult task. During the past year we followed a Scrum approach, in order to comply the team structure. As you can read here, there were one team with a small bunch of members. Now, we’re getting “bigger”. As a result, we’ll have micro-teams of two/three member each. Great chance for Kanban. Let’s give it a try.
How will we approach in the beginning?
defining a set of micro-team, that we call “task forces”
designing a Kanban board
describing personas
speaking of some ceremonies we’d like to get rid of
speaking of some ceremonies we’ll keep
describing the customer journey and the story map practices
The task forces
The term not fits very well, actually; indeed, a task force is something that could be considered as a “defcon 1” team. However, we would give the teams a label which is “strong”. To be honest, we have a little amount of time, so in the end we can say that we’re in hurry already 🙂
The Kanbard board
As we said above, we will have more task forces, most likely six. Therefore, the board will use columns (as usual) for the status management and rows (aka Swimlanes) for separating teams and projects.
The board will be created in Visual Studio Team Services, in order to use also the Source Control Manager which relies on it.
Personas
Each team member will populate a simple card, the Persona card, which is depicted in the picture below:
As you can see (in Italian), the first column is for Persona details, the second for interests and the third is the “role” which the member would like to have. I know that the last column is not included in any best practice, but I feel that some student could start to think about its job and its future. Could be interesting.
The customer journey
During the next meeting, we’ll ask the students to show us their customer journey. Each team will have to describe the journey of a typical user, with mood for each action it takes and the value which it gets by the action itself.
Conclusions
Kanban, task forces, boards, customer journey, personas, etc. This year is full of new things to get knowledge from. Also the source control manager will change. We will use git on VSTS so we will get different projects in the same place in a quicker way.