Introduction
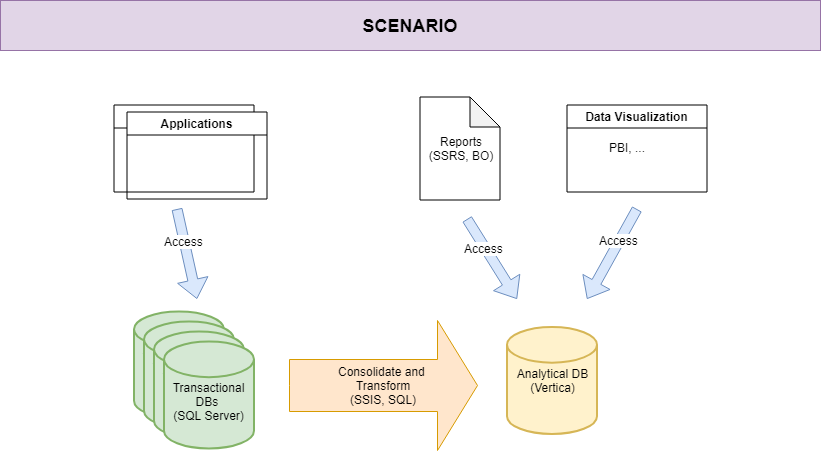
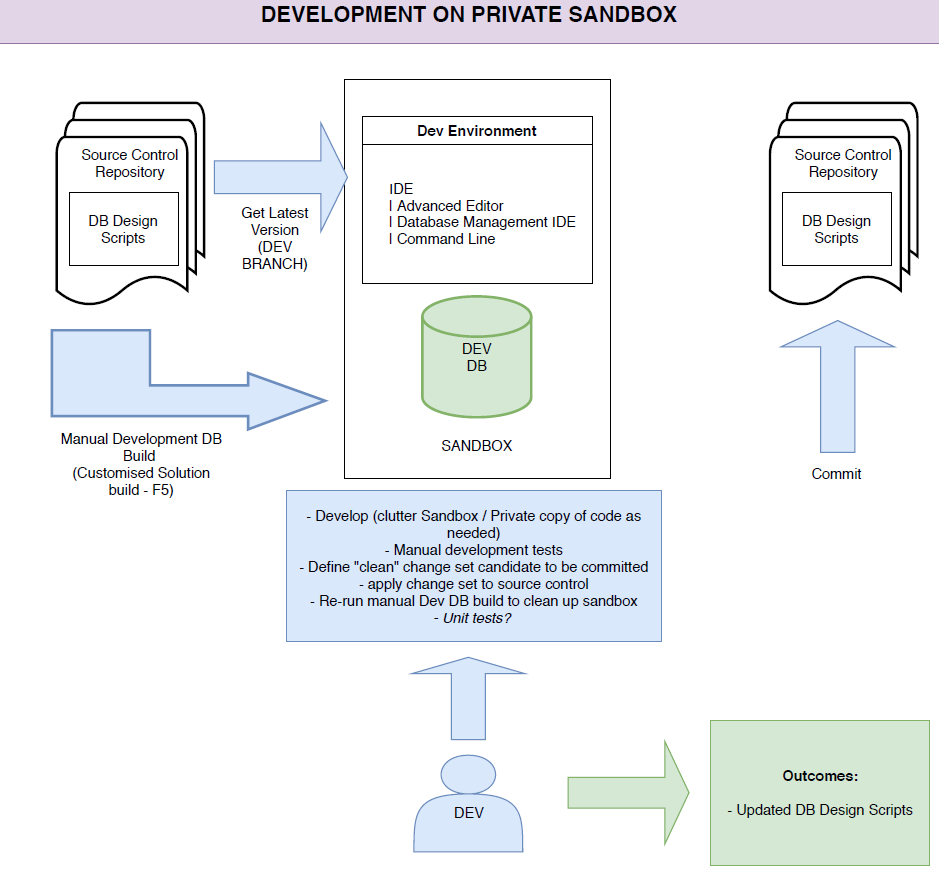
In this post, we will describe an efficient way of showing the usage statistics of our SQL Server Reporting Services hosted reports. Most of the queries below have been addressed in another article published by Steve Stedman. Even though they are really useful, the article shows their results through SQL Server Management Studio.
The problem
One of the problems that often occur in our organization as well as some of our customers, is to get immediate feedback about usage statistics of reports. Usually, the request of creating reports is out of control and some of them are executed only “that time” and not anymore. In the worst-case scenario, many of them aren’t executed at all and some of them could become even overlapped or duplicated.
Therefore, it is important to know the usage statistics, user by user and report by report, to make the reader aware of them, let him interpreting the values of the same query in multiple ways and graphical layouts. While this is not possible with a tabular format (unless you export the values using any external tools such as Excel) it is simpler when it comes to a dashboard.
Our solution: Grafana
We considered two factors: simplicity and efficiency, in order to make this first-sight dashboard. Grafana enables us to get both of them, as well as being very powerful and immediate. Even though this is not the right definition for it, we can say that “it is a portal to create dashboards using connectors, which support the most famous tools that return data”. We can find them in its marketplace. For instance, tools such as PRTG and Prometheus (monitoring), NewRelic (APM), also SQL and NoSQL data sources are supported:

Obviously, we can find SQL Server. Also, we can contribute to create others, as well as to modify Grafana itself, since it is completely an Open Source project. Examples of possible graphical representations are listed below:

Creating a dashboard is really simple. Just add each panel with a button.
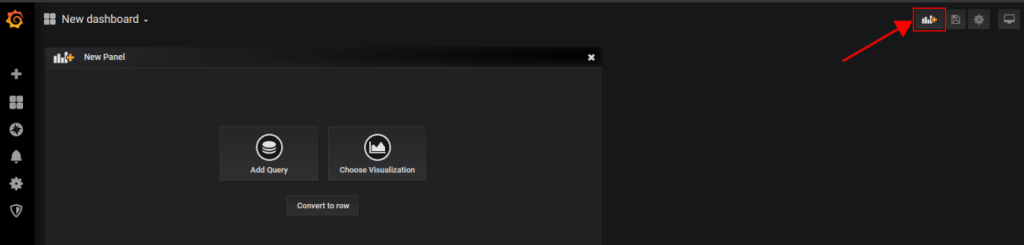
Then, write the query and modify settings to get the desired type of representation.

As mentioned before, the connectors are many. Once selected you can to configure them with parameters:

If you would like to install and configure Grafana you can read the official documentation which also includes a short guide that illustrates how to take your first steps.
That’s it!
Conclusions
With half a day of work (including the setup of the server), we have solved one of the most important problems of our customers, derived from the lack of awareness of reports deployed in production environments. We did it with very little effort and the result, as you can see, is pleasant and effective. Everything is now ready to be published every time we update the dashboards also through a delivery software (Octopus Deploy, Jenkins or Azure DevOps) so all these things fall into the second and third way of DevOps (according to The Phoenix Project): Immediate Feedback and Continuous Improvement.
Stay Tuned!