di Pier-Paolo Mammi.
I ragazzi dell’Agile@School giungono finalmente allo scontro finale con l’ultimo boss del gioco: la temibile presentazione! Avranno acquisito sufficiente esperienza per uscire indenni o quasi dalla sfida? Scopriamolo insieme.
La sfida
L’obiettivo finale del corso si basava su due cose:
- una presentazione del progetto che ne descrivesse la realizzazione e i punti di forza per un ipotetico investitore
- il videogioco vero e proprio, eseguibile e testabile da noi
Il tutto seguendo il più possibile la filosofia DevOps illustrata negli incontri fatti a scuola e utilizzando gli strumenti aziendali di uso comune, quali Azure DevOps e Git.
Ready? Fight!
Anche quest’anno, sia per avere un’opinione “esterna” rispetto a noi che abbiamo seguito i ragazzi, sia per portare prova tangibile della bontà del formato, ci ha accompagnato Alex che ha partecipato qualche anno fa all’Agile@School e che da un paio di anni lavora brillantemente in azienda con noi! Riporteremo le sue osservazioni per avere un altro punto di vista più oggettivo.
Tutti Unity – Ein
I ragazzi del team Tutti Unity hanno realizzato un solo livello del gioco, in cui Ein, il protagonista (che, ricordiamo, è l’ultimo dei cloni di Hitler creati a seguito di un esperimento e scampato al loro sterminio) deve fuggire dal laboratorio in cui si risveglia privo della memoria. Plot twist inaspettato, Ein è in realtà una ragazza! 😀
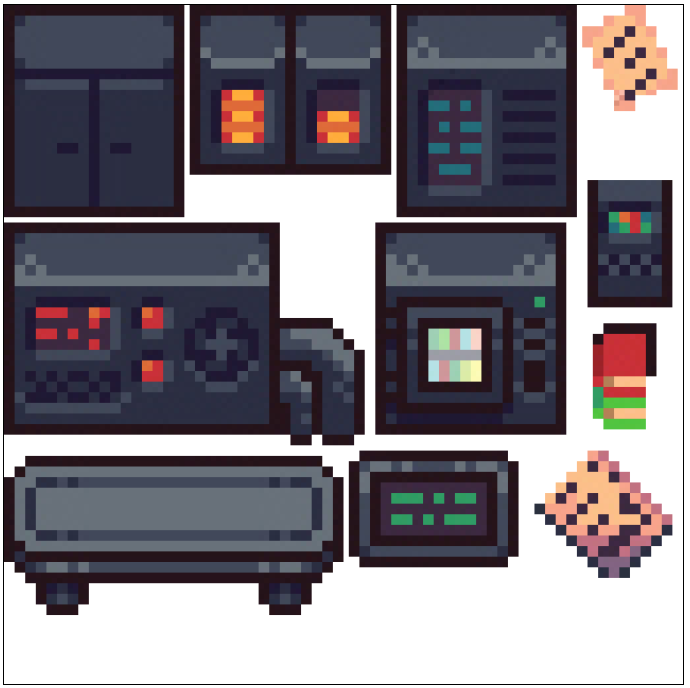
Il gioco è stato sviluppato pregevolmente con grafica in pixel-art e tutti gli aspetti grafici sono stati realizzato da zero. Non c’è stato molto tempo di introdurre interattività con l’ambiente o con altri personaggi, ma nel complesso è risultato molto apprezzabile e interessante.
Anche la presentazione è stata fatta con cura e ha illustrato i possibili sviluppi futuri del gioco, ipotizzando un rilascio a episodi.
Alex: trama veramente interessante e particolare, grafica top (apprezzabile lo stile retrò), meccaniche un po’ trascurate con risultato di un gioco che finisce subito senza fare particolari azioni.
AppeninTech – The IRA Tale
Il gioco segue le vicende di un giornalista ai tempi dell’IRA: l’impostazione è quella più classica di un libro-game, ma arricchita di alcune funzionalità che lo rendono più dinamico, come un “allineamento” fra governo e terroristi che incide sulle probabilità di sopravvivenza del protagonista e un sistema di avvenimenti casuali.
Questo progetto è risultato il più “tecnico” in quanto il codice realizzato si presta particolarmente ad essere convertito in una sorta di framework riutilizzabile.

Da evidenziare la presentazione, in quanto aveva una forte impronta volta al marketing: abbiamo poi scoperto che il ragazzo che ha contribuito alla realizzazione ha aspirazioni di social media marketing!
Alex: presentazione professionale che punta ad eventuali investitori, mostrando una roadmap dettagliata sul progetto. Molto strutturato a livello di storyline, meccaniche semplici, ma efficaci per la storia che seguono. Questo è un classico esempio dove si ha una parte backend molto elaborata a scapito della parte frontend, che risulta quindi un po’ spoglia.
Anonymous – Skyrish Adventure
Il gruppo degli Anonymous, a dispetto di aver meno competenze tecniche rispetto agli altri, è riuscito a realizzare un gioco che forse è il più in linea con la richiesta iniziale di creare un libro-game. Nonostante l’impostazione più “grafica” (invece di pagine testuali, hanno utilizzato pagine web graficamente ricche), il risultato è stato un divertente viaggio fantasy tra omaggi più o meno velati ai vari videogame del genere.
È evidente quanto i ragazzi si siano divertiti nella creazione del gioco, questa è sicuramente una componente importante nella buona riuscita di un progetto!

Alex: trama interessante (cavaliere che deve sconfiggere un boss finale), carente un po’ di animazioni dovuto a qualche intoppo, ma in generale storia corposa e ben strutturata.
What-A-Kingdom
Questo è probabilmente il progetto che ha puntato più in alto di tutti in quanto i ragazzi hanno voluto realizzare il gioco (non più un libro-game, ma un vero e proprio gestionale di un regno) utilizzando il motore Unreal Engine 5, nonostante fossero molto più ferrati con Unity. I WAK sono forse il gruppo che ha maggiormente provato sulla pelle gli effetti di una scelta tecnologica coraggiosa, in quanto non solo hanno dovuto imparare un framework per loro nuovo, ma hanno anche utilizzato una versione cutting-edge, uscita dalla beta proprio mentre creavano il gioco, e quindi più soggetta a instabilità. Come conseguenza, il gioco è sicuramente risaltato fra gli altri dal punto di vista grafico, ma i ragazzi hanno dovuto tagliare gran parte dei personaggi inizialmente pianificati per poter rispettare le scadenze.
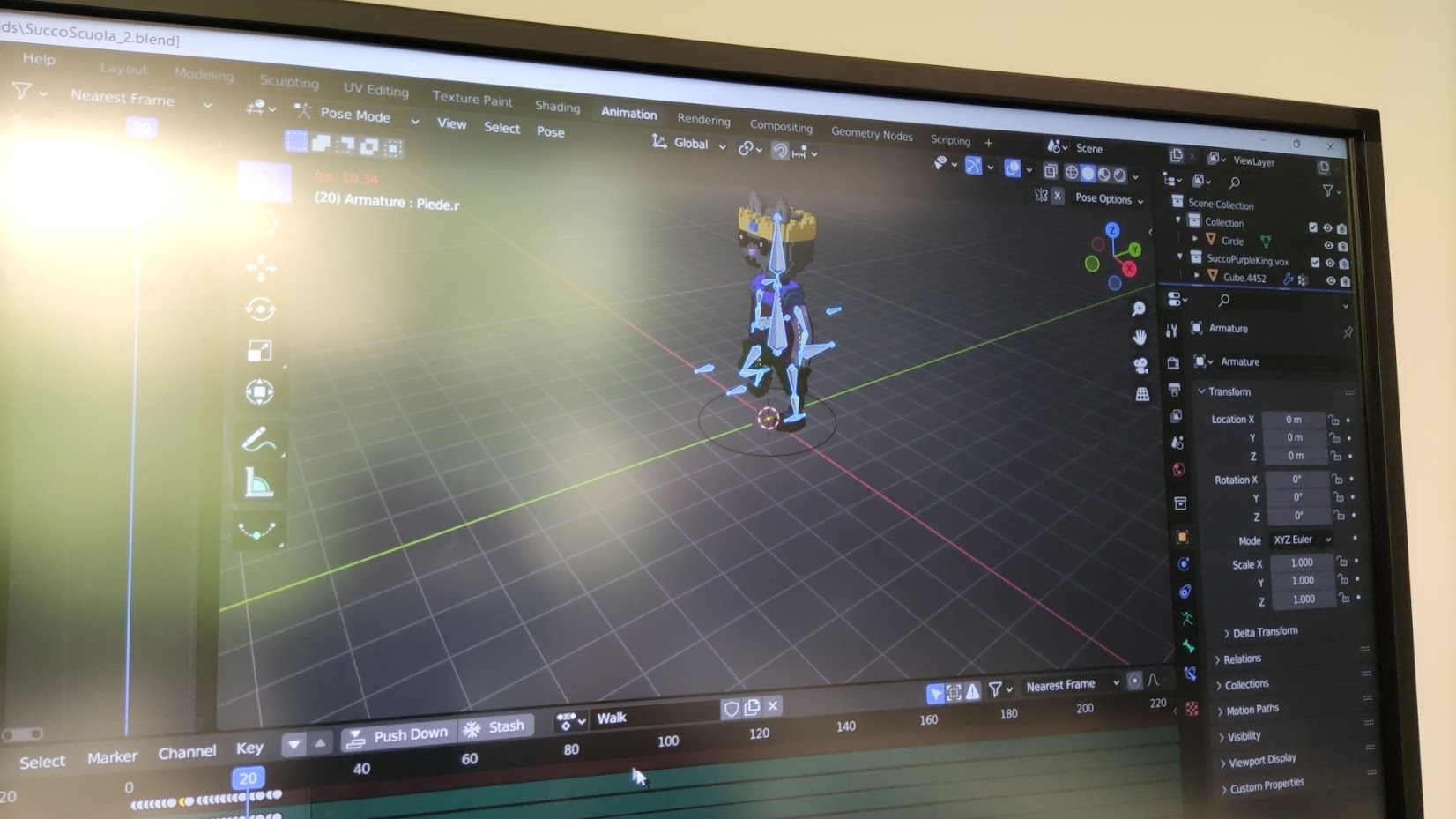
Alex: progetto ambizioso dal punto di vista delle tecnologie utilizzate (unreal engine 5). Presentazione efficace e risultato grafico degno di nota.
Conclusioni
La nostra prima considerazione emersa dopo aver visto i progetti presentati dai ragazzi è che ogni anno il livello tecnico si alza un po’ di più. Anche nelle edizioni passate ne abbiamo viste delle belle, ma quest’anno siamo rimasti particolarmente soddisfatti sia delle presentazioni che dei giochi.
Tutti i progetti erano testabili e funzionanti, nonché divertenti da giocare. Chiaramente ci sono degli spigoli da smussare, dovuti a mio avviso più che altro all’entusiasmo e alla troppa voglia di fare dei ragazzi, che in alcuni casi li ha portati a sottostimare l’entità di quello che avrebbero voluto introdurre, ma sono errori (mai come in questo caso) di gioventù!
Penso che l’obiettivo dell’Agile@School sia stato raggiunto pienamente. La realizzazione del progetto è un mezzo per dimostrare ai ragazzi cosa voglia dire lavorare in azienda, e ancora di più farlo utilizzando metodologie agili unite alla filosofia DevOps, ma soprattutto per far sperimentare loro le difficoltà tipiche che ci si trova ad affrontare, spesso in modo inaspettato, sul mondo del lavoro.
In definitiva, complimenti davvero a tutta la classe!