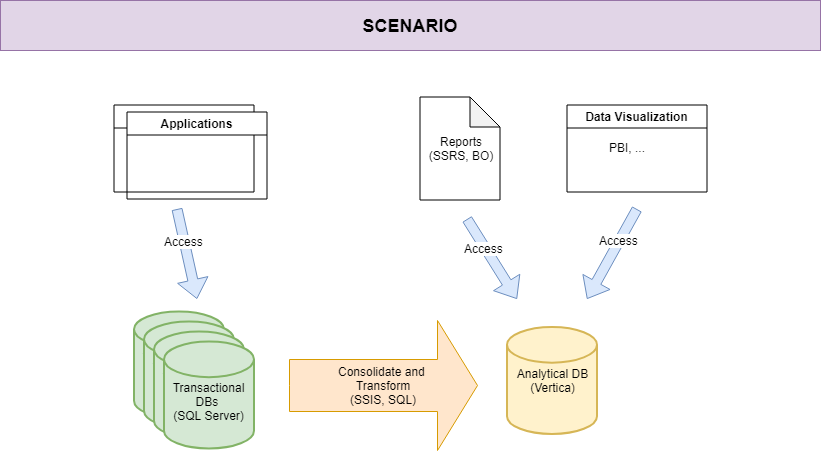
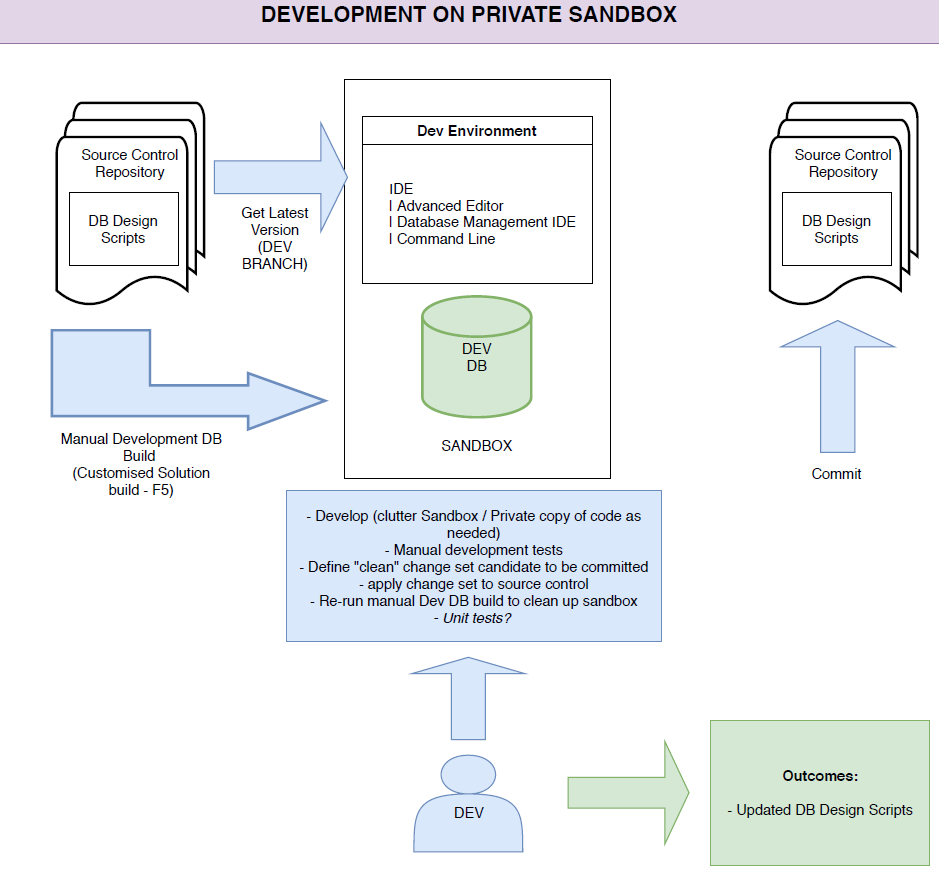
Ultimo appuntamento di Agile@School 2021. Per questa occasione ci racconta l’incontro Alex, una new entry che qualche anno fa prese parte a questa iniziativa proprio come i ragazzi. Siamo finalmente arrivati all’appuntamento che pone sotto i riflettori l’impegno e la dedizione dei ragazzi ovvero i progetti ultimati.
L’idea di fondo proposta era quella di avere una presentazione composta da una panoramica del progetto a 360 gradi partendo quindi dalla descrizione di quest’ultimo per poi procedere con pregi, difetti, punti di forza, difficoltà incontrate e motivi accattivanti per spronare un possibile giocatore ad acquistare il prodotto per poi concludere con la presa visione del progetto e la conseguente prova dello stesso da parte di noi supervisori momentaneamente nei panni di “gamer”.
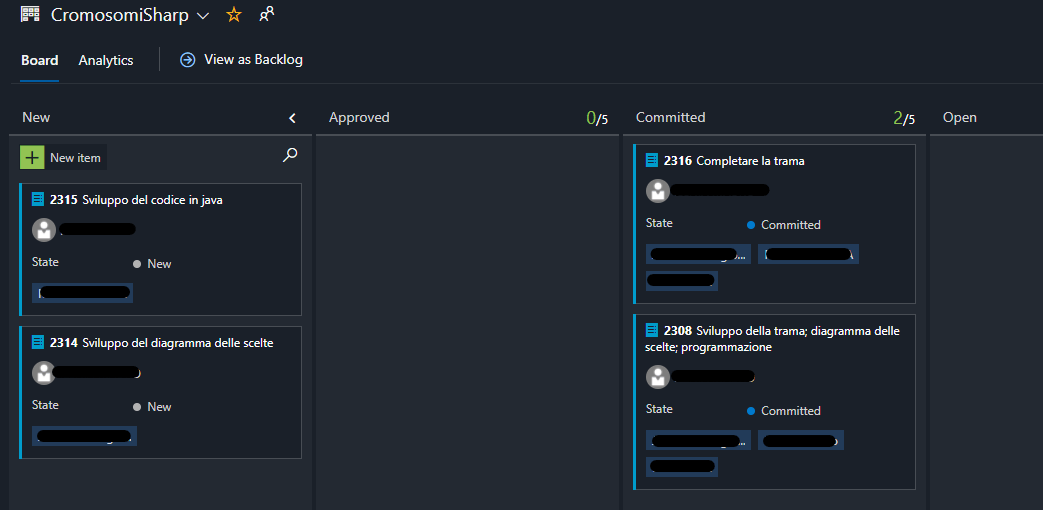
Presentazione dei progetti
Una volta superata la tensione generale il Team Cromosomi# ha preso l’iniziativa e, anche se non al completo causa assenze, è riuscito a presentare un progetto interessante caratterizzato da un gameplay che assume dinamicità grazie anche al cambio di musica in base alle scelte fatte dal giocatore.
Il gioco è stato presentato su console application e salvo qualche inserimento di dato non previsto non presentava problemi che ostacolassero la giocabilità. Un paio di consigli proposti per migliorare il tutto sono stati l’inserimento di un valore per indicare la vita del giocatore e l’inserimento di immagini che seguono il cambiamento musicale per incrementare il coinvolgimento in game.

A seguire ha preso parola il Team Fisher, team in questo caso al completo.
Presentazione ben organizzata che ha principalmente fatto focus sulle molte tecnologie utilizzate caratterizzata anche da un video realizzato su misura per l’occasione. Ben strutturata anche la storia narrativa che sta dietro al progetto. In questo caso il gioco è stato lanciato direttamente con il proprio eseguibile ed è stato provato dal sottoscritto, che non ha perso tempo per una citazione di alto calibro (infatti ho inserito subito come nome del protagonista della mia partita Rohan Kishibe… ed ho detto tutto). Gameplay con una profonda trama che fa quasi pensare ad un libro-game e che da luogo a una moltitudine di finali raggiungibili variando le scelte del nostro personaggio giocando più volte. Un problema relativo al cambio di musica durante il gioco non ha comunque influito sulla giocabilità in generale.

È stato poi il momento del Team MonkeTeck anche loro al completo.
Idea molto promettente per il progetto di questo team che grazie alla loro presentazione molto ben organizzata hanno centrato l’obbiettivo di dare informazioni che spieghino il processo creativo ma allo stesso tempo attirino il giocatore spiegando il Perché e il Come ponendo anche l’attenzione sul fattore curiosità. Gameplay che si distingue come tema dagli altri avendo come protagonista una nave a scelta che può compiere diverse azioni che possono portare anche alla distruzione della stessa se si azzerano i punti salute. Nota di merito va proprio a quest’ultimo punto, ovvero la vita o salute che finalmente vediamo implementata in uno dei progetti, l’unico fino ad ora. Molto accattivante anche la differenziazione delle statistiche in base alla nave scelta. In questo caso i consigli dati per possibili feature sono stati l’inserimento di immagini o suoni che rendano più coinvolgente la battaglia tra due navi.

Ultimo ma non per importanza è il Team GentsAndLady.py purtroppo in carenza di componenti ma carico abbastanza da sopperire alla mancanza. Presentazione abbastanza esaustiva, anche nel loro caso sarebbe stato ottimo avere una parte dedicata al Perché del gioco ma hanno compensato questa mancanza parlandone direttamente a voce, almeno per far capire a noi l’intenzione che c’era dietro. Anche in questo caso troviamo un gioco in console application preso di mira stavolta da Pier-Paolo, ormai diventato game-tester della giornata che non si è fatto sfuggire l’occasione di mettere qualche dato per far “scoppiare” tutto. Tralasciando piccoli problemi non gestiti nel complesso il gioco segue quanto promesso, quindi la storia di Napoleone in parte romanzata ma che segue un filo logico che permette lo studio giocando più volte.

Fine della corsa
Arrivati a questo punto devo ammettere che siamo stati molto sorpresi e soddisfatti dei ragazzi in quanto nonostante difficoltà, membri mancanti e tester improvvisati rompi scatole sono tutti riusciti a portare a termine un prodotto che, anche se imperfetto, risulta comunque completo.
Anche personalmente sono rimasto particolarmente stupito nel vedere i lavori realizzati dai ragazzi in quanto anche io, giusto qualche anno fa, ero al loro posto e, come loro, avevo realizzato il mio personale progetto con Engage. La differenza che ho notato maggiormente è stata la dedizione riposta in questi lavori. Quando frequentavo la scuola, non c’era questo livello nei progetti ed erano quasi tutti realizzati giusto perché “andavano fatti”. Nel mio caso il gruppo di lavoro era costituito da me :-). La voglia di fare che avevo non era particolarmente condivisa, di conseguenza, seppure non sia stato un progetto rivoluzionario, la mia “chat bella che funzionante tra smartphone e pc” l’avevo portata a termine (soddisfazione alle stelle).
Sono convinto che avvicinandosi sempre di più alle loro passioni si avrà un consenso sempre maggiore a questa iniziativa e una conseguente qualità dei progetti in continuo aumento.
Spero vivamente di poter partecipare nuovamente in futuro proprio per assistere di persona a questa evoluzione e per inserire qua e là qualche citazione di alta classe… Yare yare daze.