
Intro
As a consultant, life could be difficult when it comes to manage platform like Vertica, a columnar RDBMS by MicroFocus. Speaking about DevOps, database management systems like this one neither is well supported by built-in tools nor by any third party suites.
In my experience, which is focused on the Microsoft SQL Server world, tools like the ones made by Redgate or ApexSQL, plays a crucial role when it comes to DevOps. Unfortunately, this time I cannot find any real help. I think that it’s an exciting task, but I’ve to be careful. It’s like “reinventig the wheel” for a car (Vertica) that didn’t realize that it needs wheels. Strong and reliable wheels.
Scenario
In the scenario I’m working on, the data warehouse is managed by a layer of business logic implemented within this platform. Starting from SQL Server database populated by the application layer, the data rows pass through SQL Server Integration Services ETL packages, which transform them onto Vertica repository, and they end into a Business Objects layer (the presentation layer). Just to get the big picture, see the following diagram:
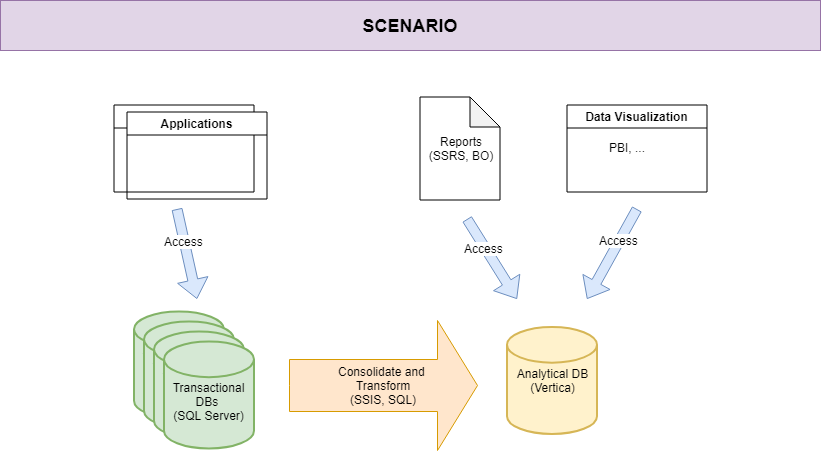
Our mission is to share DevOps knowledge, culture and tools in order to automate a set of processes which are managed manually, right now. Not a simple task, even if the guys I’m cooperating with are well-trained and powerful in tech skills. Additionally, they are enthusiast and ready to change (and we know how this is usually a trouble). We will get obstacles only from a technology perspective, actually.
After days of documentation and questions to our MicroFocus contacts, it looks like that Vertica gives us no built-in way or tool for getting an automated process during the phase of the schema comparison. Also third-party tools aren’t that good. We’re trying to dig more and more in order to find out something on the internet. However, everything it’s a “little bit” tricky. To be honest it seems that no one tried to do DevOps with Vertica, even though this is a very good platform for speeding up heavy queries on huge amount of data. Yes, we downloaded a couple of officially suggested tools, whose documentation says that we can compare from and to Vertica itself, but no one fits our scenario. No command lines, no direct integration, no script generation. If you think about automated pipelines, this can be a big problem to deal with. I think that this should be the foundation of a DevOps approach. In the end, it looks like we’re the the first team that is trying to invest efforts into that. It’s funny, though. Hopefully, someone with experience in Vertica DevOps who reads this post could help us!
(After digging more, I’ve found this article that describes almost the same scenario. I hope to reach out the author out).
Prerequisites
As a kick-off, we’ve moved into the prerequisites, starting from the most important thing: make a process that will facilitate the team’s workday, instead of wasting time due to bad choices. This process should be simple and automated.
Then, we’ve argued about the IDE used by developers, evaluating differences between before and after solutions, getting pro and cons of them all. In the end, we agreed on the following solution, development side:
- Visual Studio 2017 will be the editor for SQL Server Integration services solutions. This team, “BI team” hereafter, is working on SSIS and is separated from the application development team, at least at the moment;
- TFVC (Azure DevOps on-premises) will be the Version Control System since the BI team is already using it. We will think about a migration path to git then, but for now we’d like to avoid any distraction out of the scope;
- every get latest from the source control must synchronize all the DDL scripts for Vertica as well as the SQL Server and SSIS solutions, in order to get a sandbox with source code and the local database provisioning scripts (most likely we’ll get a virtual machine with Unix and a Vertica instance, too);
- each SSIS project must be deployed to the local SQL Server instance when running solutions into the sandbox;
- when all the SQL Server Integration Services packages are deployed, the list of Vertica DDL must be executed in order to create the database from scratch;
- Optionally, mock inserts (also from file) could be added to the database in order to get data to work on.
Our idea
As you can see, in this pipeline, we will get everything we need in our sandbox. Just a note, we can choose how to provision the instance of Vertica, in order to scale out resources from local workstations and also use another O.S. It’s up to the team.
A big picture of this process can be summarized as follows:
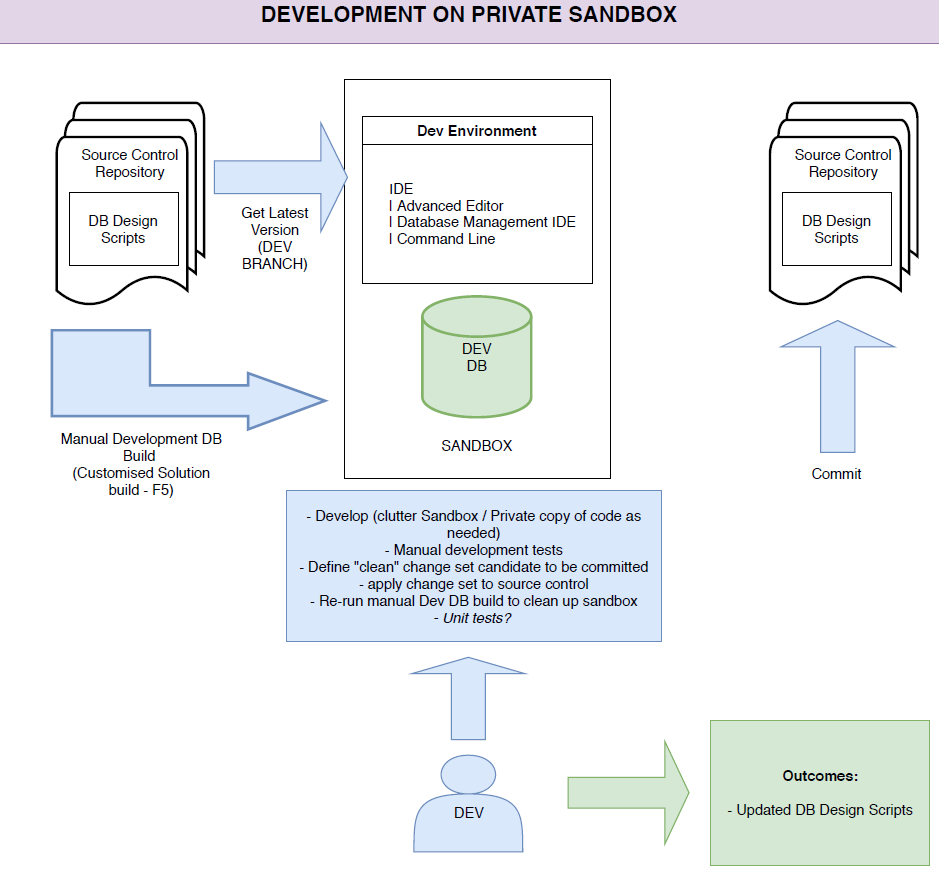
Conclusions
As we’ve seen, the big picture is ready to be implemented and also the team knows perfectly what are the goals. We already know what technologies will be involved and how to keep them all together in order to make our pipeline.
Unfortunately, we cannot find any tool that helps us, so we’re preparing to jot some lines of code down.


One thought on “DevOps journeys series – Vertica release pipeline with Azure DevOps – Ep. 01 – development (part 1)”