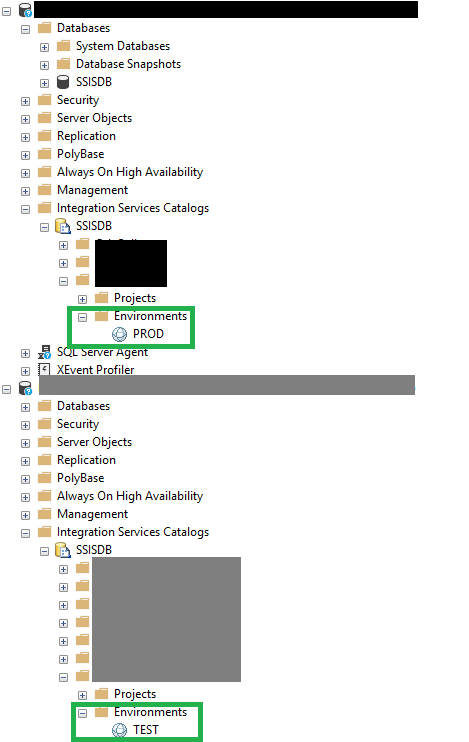
In a previous post, we’ve described the “from scratch” approach on the development side. When everything works well there, a push (or check-in) triggers the build engine. We must deal with two SQL Server instances (SSIS Servers hereafter), with an environment for each of them:
The build pipeline
The SSIS Servers keep Vertica‘s test and production mappings as well as test and production connection strings for the SQL Server databases. So we need the right variable mapping for all the scenarios, but this is not in the scope of the post, we will speak about it in the next posts. Anyways, here is how the build pipeline works:
Our build process
You may notice that the task “Copy vertica deploy scripts” is disabled. Well, to be honest, right now we’re waiting for the target integration environment.
Build process explained
In the beginning, the build server gets the source files from the repository and creates the target artifacts folder with a Powershell script. This will be the path from which we will push the artifacts to the release pipeline.
The build server generates the .ispac file for the SQL Server Integration Services packages using the dedicated task. The copy tasks will be executed:
As you can see, we’ve got a set of utilities and transformation tools, that will be executed in the release pipeline as well as the environment script. This one contains the SSISDB variables mapping and the SSIS Project configurations statements. Misc files, .sql files for environments and the .ispac file will be copied to the target artifacts folder.
The tasks above copy our template of the .nuspec file to generate the NuGet file (NuGet pack step). This is what we get using NuGet:
Then, we’re ready to publish the files to the release pipeline. We will see how the release pipeline works in the next posts.
Ehm… you miss Vertica
Yes, you’re right. But, it’ll be just a copy of .sql files to the artifacts folder. We will see how the release manager will execute them, so…
As a consultant, life could be difficult when it comes to manage platform like Vertica, a columnar RDBMS by MicroFocus. Speaking about DevOps, database management systems like this one neither is well supported by built-in tools nor by any third party suites.
In my experience, which is focused on the Microsoft SQL Server world, tools like the ones made by Redgate or ApexSQL, plays a crucial role when it comes to DevOps. Unfortunately, this time I cannot find any real help. I think that it’s an exciting task, but I’ve to be careful. It’s like “reinventig the wheel” for a car (Vertica) that didn’t realize that it needs wheels. Strong and reliable wheels.
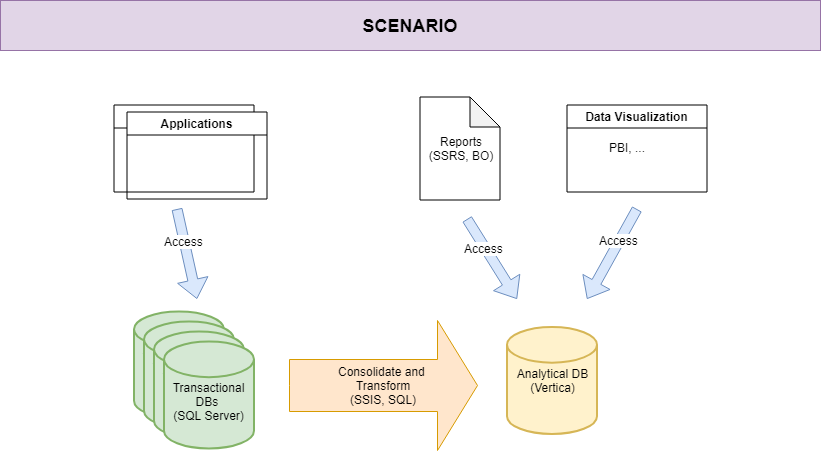
Scenario
In the scenario I’m working on, the data warehouse is managed by a layer of business logic implemented within this platform. Starting from SQL Server database populated by the application layer, the data rows pass through SQL Server Integration Services ETL packages, which transform them onto Vertica repository, and they end into a Business Objects layer (the presentation layer). Just to get the big picture, see the following diagram:
Our mission is to share DevOps knowledge, culture and tools in order to automate a set of processes which are managed manually, right now. Not a simple task, even if the guys I’m cooperating with are well-trained and powerful in tech skills. Additionally, they are enthusiast and ready to change (and we know how this is usually a trouble). We will get obstacles only from a technology perspective, actually.
After days of documentation and questions to our MicroFocus contacts, it looks like that Vertica gives us no built-in way or tool for getting an automated process during the phase of the schema comparison. Also third-party tools aren’t that good. We’re trying to dig more and more in order to find out something on the internet. However, everything it’s a “little bit” tricky. To be honest it seems that no one tried to do DevOps with Vertica, even though this is a very good platform for speeding up heavy queries on huge amount of data. Yes, we downloaded a couple of officially suggested tools, whose documentation says that we can compare from and to Vertica itself, but no one fits our scenario. No command lines, no direct integration, no script generation. If you think about automated pipelines, this can be a big problem to deal with. I think that this should be the foundation of a DevOps approach. In the end, it looks like we’re the the first team that is trying to invest efforts into that. It’s funny, though. Hopefully, someone with experience in Vertica DevOps who reads this post could help us!
(After digging more, I’ve found this article that describes almost the same scenario. I hope to reach out the author out).
Prerequisites
As a kick-off, we’ve moved into the prerequisites, starting from the most important thing: make a process that will facilitate the team’s workday, instead of wasting time due to bad choices. This process should be simple and automated.
Then, we’ve argued about the IDE used by developers, evaluating differences between before and after solutions, getting pro and cons of them all. In the end, we agreed on the following solution, development side:
Visual Studio 2017 will be the editor for SQL Server Integration services solutions. This team, “BI team” hereafter, is working on SSIS and is separated from the application development team, at least at the moment;
TFVC (Azure DevOps on-premises) will be the Version Control System since the BI team is already using it. We will think about a migration path to git then, but for now we’d like to avoid any distraction out of the scope;
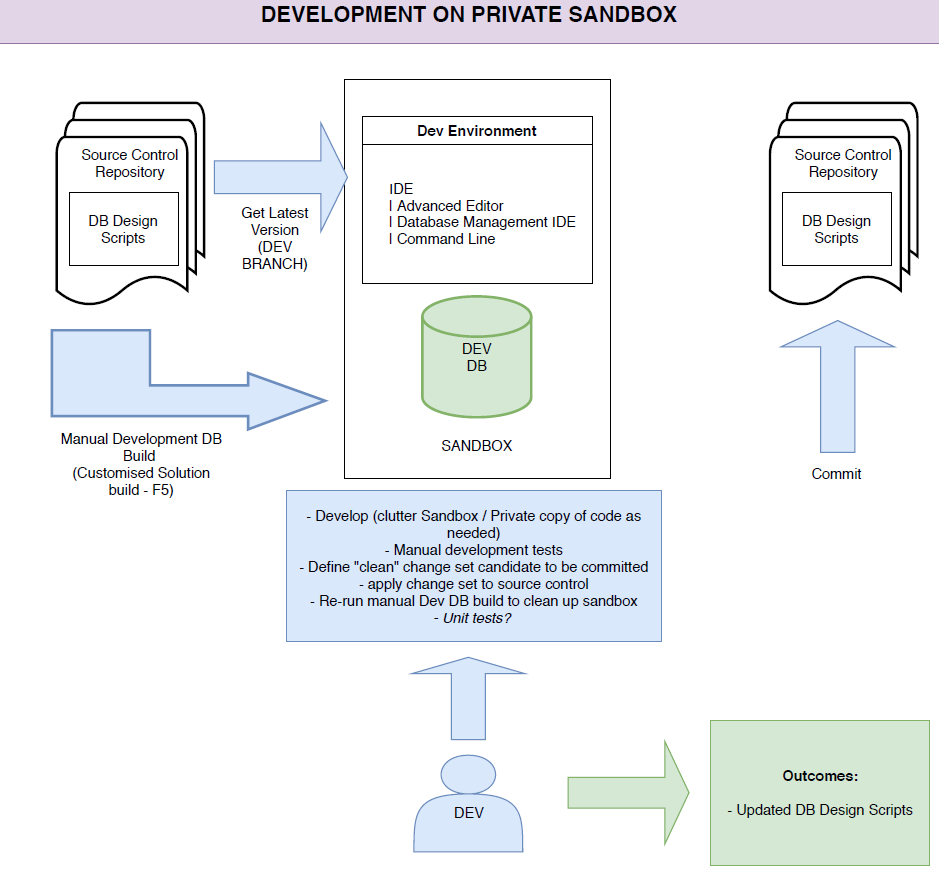
every get latest from the source control must synchronize all the DDL scripts for Vertica as well as the SQL Server and SSIS solutions, in order to get a sandbox with source code and the local database provisioning scripts (most likely we’ll get a virtual machine with Unix and a Vertica instance, too);
each SSIS project must be deployed to the local SQL Server instance when running solutions into the sandbox;
when all the SQL Server Integration Services packages are deployed, the list of Vertica DDL must be executed in order to create the database from scratch;
Optionally, mock inserts (also from file) could be added to the database in order to get data to work on.
Our idea
As you can see, in this pipeline, we will get everything we need in our sandbox. Just a note, we can choose how to provision the instance of Vertica, in order to scale out resources from local workstations and also use another O.S. It’s up to the team.
A big picture of this process can be summarized as follows:
Conclusions
As we’ve seen, the big picture is ready to be implemented and also the team knows perfectly what are the goals. We already know what technologies will be involved and how to keep them all together in order to make our pipeline.
Unfortunately, we cannot find any tool that helps us, so we’re preparing to jot some lines of code down.
DevOpsHeroes has been a great event, again! We didn’t expect so many people and we could not imagine that the feedback would be so good. Quick facts:
Subscription: 244 (150 the past year)
Attendees: 122 (94 the past year)
drop: 50% (38% the past year)
Attendee’s satisfaction
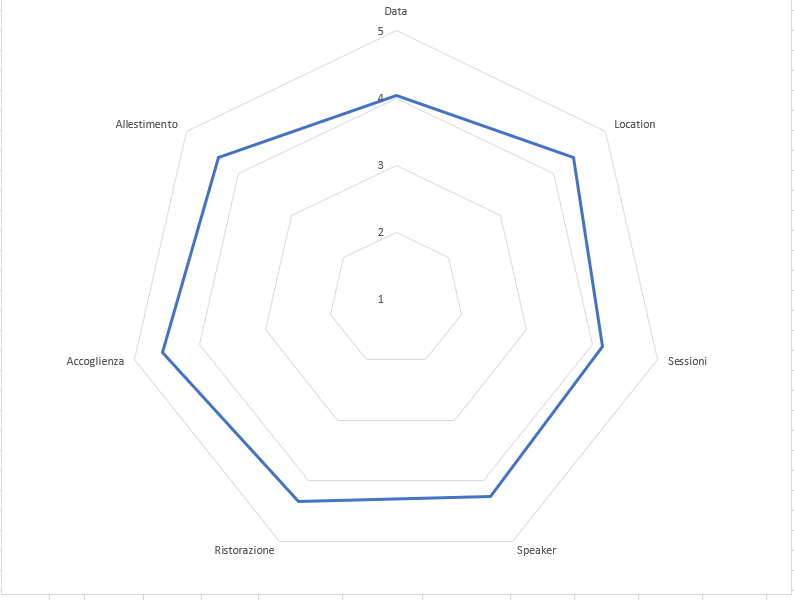
The following radar chart is about the event date, location, quality of the sessions, quality of the speakers, food, hospitality, event design, and kits:
As we can see, the overall satisfaction is really high (4/5)! The blue line is related to the audience which already has attended our event (40%) and the orange one represents the first-timers (60%).
Indeed, we’ve got a good feedback also for the following questions:
will you attend again?
Sure, 45%
Most likely, 33%
Likely, 22%
will you suggest the event to other people?
Sure, 76%
Most likely, 21%
Likely, 3%
Conclusions
We’re really proud of the third edition of DevOpsHeroes. Engage IT Services and Xebir did a great job together, and, hopefully, both companies will cooperate in the future in order to provide new formats and events like this one. A special thanks goes to Scott Ambler, and also to Italian Agile Moviment for sponsoring and supporting the organisation.
Years ago, with SQL Server 2016 release, Microsoft came up with a separated brand new version of SQL Server Management Studio. It’s been a happy day for the SQL Server community and database developers.
Shortly afterwards, our company started to migrate every instances from older version of SQL Server to the 2016, using SSMS 17.*. Developers have already jumped into Visual Studio 2017 and everything seemed to work like a charm, until we started deploying integration services via the new SSMS, after we converted them to 2016 TargetServerVersion (which is NOT the Project Version).
The TargetServerVersion is the SSIS version, also for the deploy operations, while the Project Version setting tells to Visual Studio how to open projects based on .dtproj specifications on the XML projects definitions.
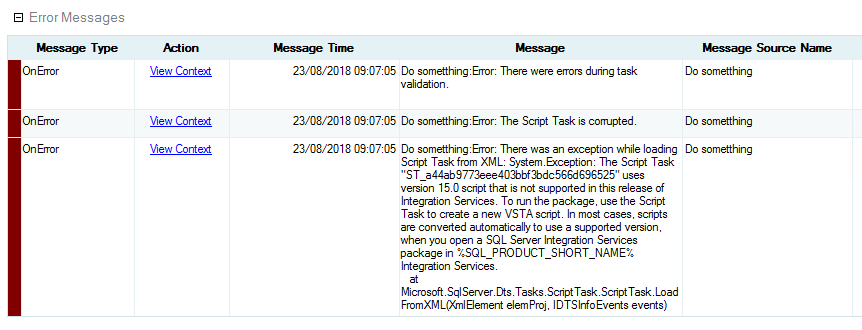
Some days ago I’ve realized that after updating to the latest build of SSMS (17.8.1), the .ispac deployment is actually executing the latest build of the Integration Services Deployment wizard (aka ISDeploymentWizard.exe). As a result every deploy of .ispac files, regardless trying double click or deploying directly from the Integration Services Catalog, the SSISDB, failed with one of the most scaring error message ever:
“[…] The Script Task <unique_name> uses version 15.0 script that is not supported in this release of Integration Services […]“
What? Why? I’ve a workstation with SQL Server 2016 and the related Integration Services 13.0:
The computer I’m speaking of has the same build of mine, nobody has installed any other Integration Services versions anywhere. Andy Leonard explained this behavior in this blog post. Unfortunately, in my scenario, I cannot solve the problem.
Let’s try to explain better.
Scenario
The workstation I’m working on has SQL Server 2016 (build 13.0.5149.0) and Integration Services 13.0 on Windows 10 Pro. I’ve got a simple package with a single script task which does literally anything: As Andy suggested us, I’ve changed the TargetServerVersion to SQL Server 2016, so I’ve got C# 2015 compiler for scripts:
First execution and deploy
Executing it locally, nothing happens, but it happens in a green way (success):
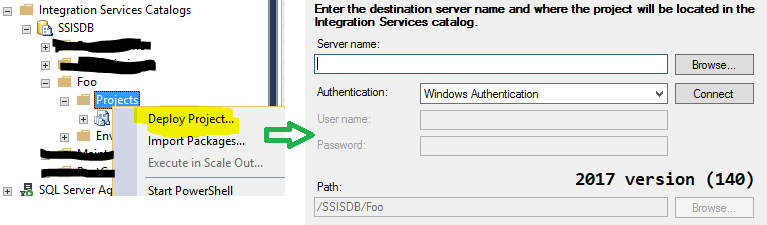
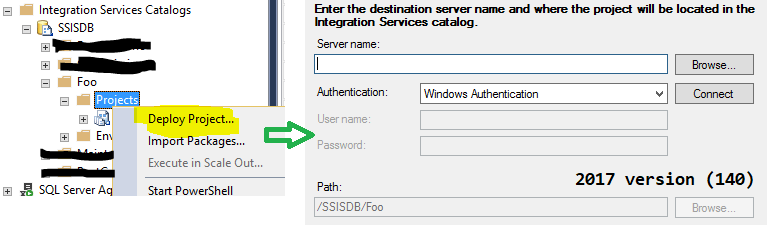
Ok, now we’re going to deploy to the other machine, generating the .ispac file and double clickin on it. It’s important to make sure that you’re double-cliking the .ispac file. Do not right click on the Integration Service Catalog project folders because SSMS will execute the latest build of ISDeploymentWizard.exe by design.
deploy from SSMS 17.8.1
When double clicking, the app selector should use the version related to the TargetServerVersion setting of the .ispac. This works for many of my other computers. But for one of them, here is the screen:
double click on .ispac file
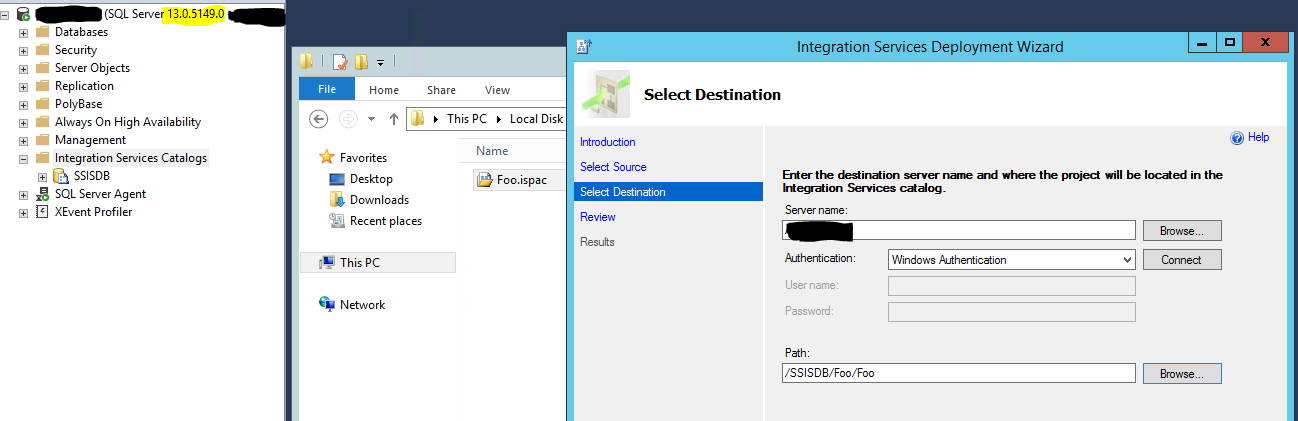
Hey! This is 2017 also when clicking on .ispac file. Let’s try to deploy using the new tool. The deploy succeeded.
And now, let’s try to validate the package execution via SSISDB, right clicking on the project itself and selecting “Validate…”. This is the result of the empty script package validation:
I’ve tried on six different machines, five ran successfully and ONLY ONE returned the above error message. Still stuck in the middle.
What have we changed?
Just the setup of SSMS (17.8.1) updating the 17.7 one. Once again, the same setup on all six machines. Five by six worked, this one is trying to kill me.
For some strange reason, something (I assure you all, not someone) has changed the registry in the .ispac application association, maybe when double clicking for the first time the file in a pending reboot (?). We’re still investigating, since we used to avoid any change in production without permissions and processes. That said, it’s weird. And it was so difficult to get.
Solution
Easy to say, now that we’ve figured out the root consequence. Not so good, but changing the registry on the key HKEY_CLASSES_ROOT\.ispac with the 130 executable (IntegrationServices.ProjectDeploymentFile.130) fixed the unwanted behavior. The key has been set to IntegrationServices.ProjectDeploymentFile.140 right after the update from 17.7 and 17.8.1.
Instead of changing it via regedit, you can try an “open with…” with “use default” checked in order to force the association between .ispac file and the right ISDeploymentWizard.exe version. But this time, in this machine, it didn’t work. This is the reason why I tried the regedit action.
Conclusions
I have to say a big thanks to Andrea Amantini, one of my peer, which is well known for his ability to find out “a needle in a haystack.”. Strange things happened here. A combination of Murphy’s law, a sort of “black” friday and a pending reboot. Hopefully this helps someone, at least.
DevOpsHeroes has been a great event. We didn’t expect so many people and we could not imagine that the feedback would be so good. Quick facts:
Subscription: 150
Attendees: 93
drop: 38%
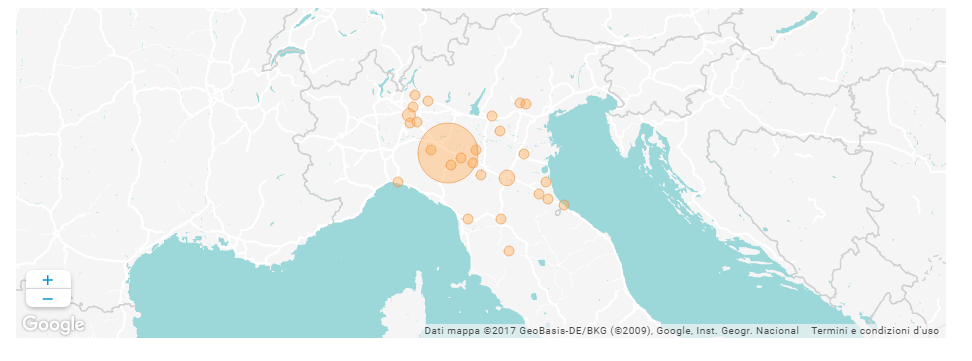
Attendees’ County/Region (breakdown):
Attendee’s satisfaction
The following radar chart is about the event date, location, quality of the sessions, quality of the speakers, food, hospitality, event design and kits:
As we can see, the overall satisfaction is really high (4/5) and everything on the venue was rated higher!
Indeed, we’ve received a good feedback also for the following questions:
will you attend again?
Sure, 26%
Most likely, 52%
Likely, 20%
will you suggest the event to other people?
Sure, 59%
Most likely, 32%
Likely, 9%
Additionally, we’ve got 87% of new entries, awesome!
Some considerations
We have to work for the next year’s edition, in order to improve our organisation, but in the end we did very good. The number of event feedback is close to the total number of attendees, so they can be considered the source of any suggestion.
Speaking about tech sessions, including the speech made by Martin Woodward, we’ve received a set of important suggestions. We already know, our speakers are skilled and passionated, but how can we understand the people’s opinions without these surveys?
I’ve spent last two nights in browsing and reading hundreds of those sheets (almost 500, thanks again). Each of them has the following questions:
Did the session meet your expectations?
Was the topic interesting?
Was the speech valuable?
What about the quality of the presentation?
How’s the speaker? Funny, expert, teacher, motivator, storyteller?
As we can see in the picture below, left side, the overall satisfaction is very high once again (expectations, interesting, valuable and presentation). On the right side, we notice that our speakers are considered experts and somehow funny and storyteller:
Conclusions
We’re really proud of the second edition of DevOpsHeroes. Engage IT Services and Upgrade did a great job together, and, hopefully, both companies will cooperate in the future in order to provide new formats and events like this one. A special thanks goes to Martin Woodward (Microsoft), which “crossed the seven seas” for being with us, and also to HPE for sponsoring and supporting the organisation. A great kudos goes to Silvio Di Benedetto and Giuliano Latini, who managed and followed the live streaming and the session recordings (coming soon here).
Summer holidays are coming, finally. This year I’m really tired, maybe because I’ve spent my energies on learning English, working hard for my own Company, following external school and non-school projects. But I can say that one of the most heavy part has been the organization of the following two events:







 As Andy suggested us, I’ve changed the TargetServerVersion to SQL Server 2016, so I’ve got C# 2015 compiler for scripts:
As Andy suggested us, I’ve changed the TargetServerVersion to SQL Server 2016, so I’ve got C# 2015 compiler for scripts: