As described in this article, PASS “is ceasing all regular operations, effective January 15, 2021”. The 2020 has been one of the worst year ever for many companies and that is true also for the one behind the Professional Association of SQL Server.
That being said, our beloved SQL Saturdays (Parma, Pordenone, Milan, Turin, Ancona, Verona, etc.) will not be held anymore. To be honest, SQLSaturdays have been great from many perspectives:
Community aggregation
Offline networking
Content sharing
People relationship
So what? Are we losing these opportunities forever?
Well, the #sqlfamily is great and I’m proud to be part of it. But, the question is, how can we keep the value of the SQLSaturdays? We’ll start from scratch with the spirit of one of the strongest tech community ever known.
A migration, no matter what is the involved set of technologies, is one of the hardest tasks to deal with. Not just for IT. However, working with the culture of many companies, I’ve got confirmation that the tool should be considered at the end of the migration process. Indeed, after setting up the ceremonies, involving the patterns of the team working, switching the methodologies from legacy to lean/iterative, it comes finally to understand how to choose from the available tools (part of the “enterprise awareness”) and including a set of new tools, optionally. The goal is to get all the stuff which fit the real scenario.
This post is a quick step by step guide to migrate work items from Jira cloud to Azure DevOps Services. I’m going to describe the last step of one of my customers’ migration.
Getting started
Before going in-depth with technical details, I would like to share some tips. As we have already said, the migrations are complex tasks. Mandatory requirements should be a strong knowledge in terms of business and team management, enterprise awareness and years of experience on different real scenarios.
We must avoid any decision if our ideas and targets are not clear. Indeed, another important requirement is to understand in depth the workflows you will work on, both the legacy one and the new one you’re figuring out. Some of the question we should ask ourselves are:
Do we require these steps? And what about these work items?
Is this state workflow good for us? Should we change it? How?
Do we require to preserve relationships and items’ history?
Can we keep something which is working very well now? If so, what tools we’re thinking about?
The software selection
The software selection has ended up on a tool made by Solidify (Thanks to the experienced members of our getlatestversion.eu community). Anyways, you can find more of them. For example:
When exporting from Jira, the CLI implemented by Solidify connects to the Jira server (cloud by default and on-premises when configured), executes a JQL query for extracting the Jira so-called “Issues”, evaluates and applies the mapping between users, work items, relationships and states, and exports a JSON file for each item.
When importing to Azure DevOps, the CLI imports the output JSON files using the same mapping configured into the configuration file in the exporting phase.
Why this tool? Because it has a couple of simple command lines and it consumes a JSON configuration which is clear. Additionally, it has many default behaviors, like the built-in configuration for SCRUM, agile and basic process templates, which allows us to forget about the complexity of both the source and target software.
Executing the tool
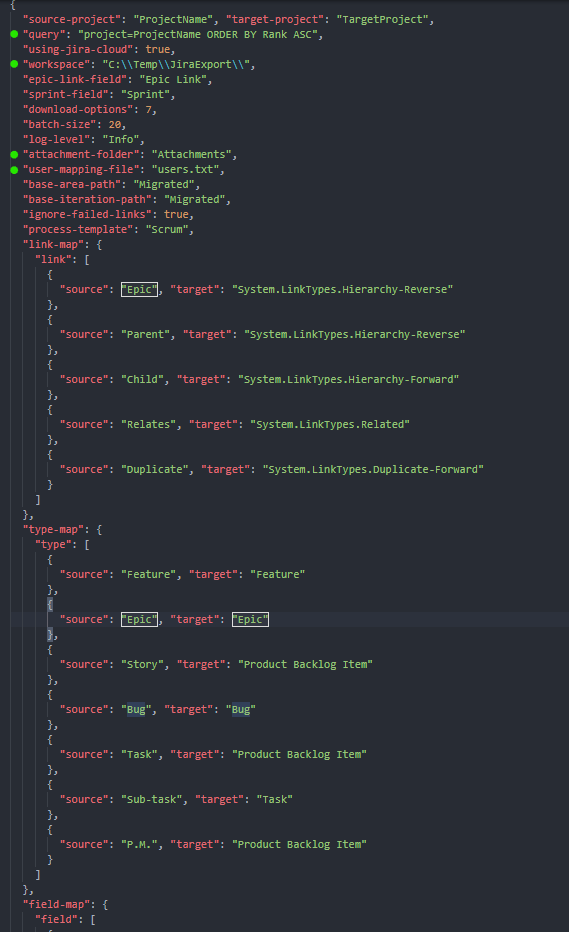
The scenario I’ve dealt with, Jira side, has been configured with many states, also with the same meaning (due to the legacy setup and different team’s approach) and with custom workflows/links. On the other hand, Azure DevOps side, I’ve created a customized Scrum template, with just two new work item types, which should support some of the customized source behaviors, and a couple of new states.
So the tool has been configured as depicted in the following JSON (just a subset of maps):
Just that. Notice that we can configure project names, the JQL query for gathering issues, working folder names and the file for the user mappings.
create a folder called C:/Temp/JiraExport (you can configure this editing the JSON config file)
create a file called “users.txt” within that folder and put into it a list of jirauser@domain.ext=AzDOs@domain.ext records
please note that the Jira user can be represented without the domain, depending on its configuration
copy the JSON configuration file (based on he template we’re going to apply when importing) into the JiraExport folder
modify the file in the maps section: link-map, type-map, field-map, and so on.
get the credentials (as admin) and the Jira server URL
make your command line, which should look like the following: jira-export -u username@domain.ext -p userPwd --url https://jiraurl.ext --config config-scrum.json --force
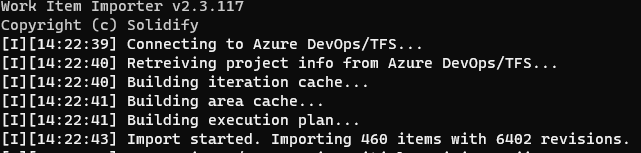
run the command and look for the JSON files into the JiraExport folder
look for any warning/error like the following and correct them (this will help you to import without any breaking change)
The missing mapping between Wip status and Story item
How to import to Azure DevOps
It’s time to execute the second command line, wi-import. As we can see, we have to get a personal access token (PAT) from Azure DevOps, as described in the documentation, with the full access.
Coming back to the configuration, we should pay attention to base-area-path and base-iteration-path. With these, we can choose the target of our migration, in terms of area and iteration. This means that we can manage our items after the import has been completed. With a query, for example, we can remove everything and start over with the migration. Cool.
The command should like the following:
wi-import --token PAT --url https://dev.azure.com/org --config config-scrum.json --force
After ten minutes we’ve got new areas and iterations:
The Azure DevOps hierarchy of items (except for the Features, which I’ve not mapped) has been preserved and also the history of any item:
Conclusions
In a couple of days, we’ve migrated everything related to work items from Jira to Azure DevOps. Most of the time should be invested in configuring the JSON mappings and, for sure, to check for the errors caught during exporting items. Finally, after importing into AzDOs, you can start over and over, removing all the items under the pre-configured area/iteration, until everything looks good.
Anche quest’anno grandissima esperienza. Un grazie a Christian Memoli (docente di Tecnologia) e al nostro istruttore Pier-Paolo Mammi, che ha fatto veramente un bel lavoro.
Siamo infine giunti al termine della nostra avventura “agile” coi ragazzi del I.I.S.S. Gadda; è stato un viaggio pieno di concetti nuovi, di abitudini per lo più sconosciute e difficili da fare proprie, soprattutto in un percorso così breve. Cosa avranno imparato i ragazzi e cosa sarà rimasto loro per il futuro? Intanto, scopriamo com’è andata la presentazione dei progetti.
Esaminare il file README e le grafiche delle applicazioni
Nella precedente lezione Pier-Paolo ha dato un paio di esercizi: compilare il README.md dei progetti GitHub, visualizzato in automatico all’apertura del repository da browser e realizzare alcuni mock-up dell’interfaccia grafica per le applicazioni che hanno sviluppato finora. Eravamo curiosi di capire come i ragazzi si sarebbero immaginati la propria applicazione, così come quale sarebbe stata la loro “sensibilità” verso la user experience.
Già dalle diverse modalità con cui i progetti sono stati presentati abbiamo notato con piacere il buon livello di organizzazione e affiatamento dei team. In particolar modo ci ha colpito il team TEP, che non solo ha realizzato un file readme corposo, con una descrizione estesa delle funzionalità dell’applicazione e istruzioni piuttosto dettagliate per l’apertura in locale del loro progetto, ma anche ricco di linee guida da seguire per la creazione della parte grafica, con i colori dell’applicazione, gli stili, ecc.
Le diverse schermate sono poi state descritte dai rispettivi creatori, tuttavia risulta evidente la coerenza generale con cui queste sono state ideate. Nonostante la grafica fosse minimale (com’è giusto che sia in un mock-up), questa risultava di immediata comprensione e fruibilità da parte di un possibile utente finale, per cui sarebbe stata tranquillamente impiegabile in una app reale.
Durante la visione del codice è risaltato il corretto utilizzo del branching negli sviluppi (affrontato in prcedenza) portati avanti dai vari membri.
Il secondo gruppo a dare soddisfazione è stato quello che ha progettato il Casinò. File readme ben compilato, è vero, ma degno di nota è stato soprattutto il mock-up della loro applicazione: una sola schermata, ma molto vicina ad una vera pagina iniziale di un sito di gaming, poiché costruita con molto colore e con tanta grafica. Non solo, anche funzionante!
Gli altri due gruppi sono riusciti a realizzare dei mock-up significativi, ma con qualche “pecca”: quello presentato dal team CUP, impaginato bene ma troppo simile a un sito vero e proprio, tanto era ricco di contenuti. Non è stata sottolineata la modalità di utilizzo dell’applicazione. I ragazzi del team ClasseViva sono stati più “in tema”, ma le schermate presentavano qualche incertezza a livello di esperienza utente. Pier-Paolo ha quindi suggerito di scegliere i componenti dell’interfaccia in modo da renderla più intuitiva e immediata per l’utente finale (ad esempio, prediligere i pulsanti invece delle tendine di selezione e via discorrendo).
Tirando le somme
In queste otto lezioni abbiamo parlato di come ci si approccia allo sviluppo “agile”: cosa sono le user story e come queste diventano work item in un sistema di gestione dei progetti (in particolare Azure DevOps); cosa sono le boards, come si utilizza il backlog e la presa in carico dei task; infine, come sia importante abituarsi alle cosiddette cerimonie (stima dei work item, review quotidiana, etc.). Abbiamo poi complicato il tutto coinvolgendo Git e le sue caratteristiche più avanzate, come ad esempio il branching e la risoluzione dei conflitti, nonché la necessità di collegare la gestione del codice ai work item per tracciare contemporaneamente gli sviluppi e l’andamento del progetto. Infine abbiamo condito il tutto con qualche concetto normalmente tralasciato quando si parla di sviluppo, come la creazione della documentazione (tecnica e funzionale) e la realizzazione di mock-up per la UI.
Conclusioni
A ben guardare, anche se per me il tempo è quasi volato, abbiamo fatte vedere davvero tante cose a questi giovani. Confidiamo che per gli studenti il corso (seppure il nome è riduttivo vista l’esperienza) non sia stato semplicemente uno fra tanti, ma che sia visto come un punto di partenza, uno stimolo in più per approfondire e fare propri tutti i concetti, soprattutto per quando si troveranno ad affrontare un’esperienza lavorativa. In più, la difficoltà imprevista della quarantena (a nostro avviso, affrontata alla grande) ci ha “costretti” a condurre il corso in modalità online. Beh, possiamo ritenerci decisamente soddisfatti.
Chiudo (un po’ a malincuore) ringraziando in primis il professor Christian Memoli e i dirigenti dell’I.I.S.S. Gadda, che ci hanno nuovamente dato fiducia nel portare avanti il progetto Agile@School; naturalmente i ringraziamenti si estendono, al nostro docente ormai ufficiale, Pier-Paolo, che ha svolto un lavoro eccellente, di cui ero praticamente certo.
Last, but not least non posso che ringraziare anche i ragazzi stessi, sia per aver sopportato le nostre pressioni, sia per aver ascoltato e messo a frutto quanto imparato: senza di loro questo progetto non avrebbe neanche senso di esistere!
Settima lezione. Questa volta non parleremo dell’essere “online” a lezione come precedentemente descritto, ormai è un dato di fatto. Notizia di oggi, invece, quella che oltre agli esami di maturità effettuati online, in caso di protrarsi della situazione di emergenza, a settembre tutte le lezioni verranno tenute in didattica a distanza. In tal caso direi che siamo già pronti.
In questa lezione, i ragazzi hanno potuto provare con mano cosa accade quando non si applica una metodologia agile; il professore si infuria! Ma quali sono stati i passi falsi? Proviamo a vederli più in dettaglio, al fine di analizzare meglio la problematica ed evitare che si ripeta in futuro.
Uso scorretto degli strumenti e disorganizzazione
In un caso, il codice scritto da ciascuno dei membri di un team non è stato portato sul repository GitHub, bensì unicamente memorizzato sul proprio computer. E non è nemmeno stato installato il software necessario per interfacciarsi al source control. Nell’altro, non siamo stati in grado di vedere nulla. Indovinate il motivo… nessuno dei membri del gruppo aveva a disposizione un computer dal quale poter condividere lo schermo, poiché erano tutti collegati solo tramite smartphone.
Entrambi i casi rappresentano punti critici nell’adozione dell’agile development:
nel primo, la mancata adozione degli strumenti e dei processi scelti, che in un ambito aziendale hanno una precisa ragione d’essere. Possibili conseguenze sono disallineamento nel codice e introduzione di anomalie, se non addirittura perdita di codice (“se si rompe il PC?”);
il secondo, la mancanza di organizzazione, che è un sottoinsieme della mancanza di comunicazione, punto chiave della mentalità agile: in questo caso, pensate alla “brutta figura” che si fa nel non presentare nulla ai committenti perché nessuno ha un computer. Quasi anacronistico. E pensare a un piano di riserva?
Torniamo alla teoria: la documentazione
Siamo certi che i ragazzi abbiano imparato tanto da questa serie di difficoltà. Tuttavia, nonostante il blocco, la lezione è andata avanti con un po’ di teoria. Oggi è stato il momento della documentazione, aspetto spesso trascurato, se non frainteso, dello sviluppo del software. Avete sentito bene, dello “sviluppo del software”. Nessuno si può salvare, nemmeno gli sviluppatori.
Pier-Paolo ha quindi evidenziato la differenza fra la documentazione tecnica e quella funzionale, entrambe necessarie, ma diverse sia nell’obiettivo/destinatario che nella stesura. Se nella prima è possibile adottare un linguaggio di settore e scendere nel dettaglio delle implementazioni (pratica consigliata per favorire la documentazione interna del team), nella documentazione funzionale troveremo una descrizione dell’operatività, corredata di schermate ed esempi concreti. Non dimentichiamo che quest’ultima è rivolta soprattutto all’utente finale del software.
Per far capire meglio questo aspetto abbiamo mostrato ai ragazzi alcuni esempi di quanto realmente realizzato sul lavoro e abbiamo dato loro due semplici esercizi: uno, provare a compilare il file README.md sul repository GitHub, con una descrizione del proprio progetto e le istruzioni per scaricarlo e aprirlo; due, disegnare alcune schermate di come immaginano l’interfaccia utente che il loro software deve avere, utilizzando gli strumenti di mocking che preferiscono.
Conclusioni
La lezione si è chiusa con la presentazione del codice degli altri gruppi, quelli che hanno commesso meno errori dei primi. Una cosa ci ha colpito in particolare, la realizzazione del progetto “Casinò online”, in quanto i ragazzi hanno già adottato una soluzione che facilita l’integrazione del codice in un’interfaccia grafica; un approccio quasi da architetti software, bravi!
Ci avviciniamo purtroppo alla fine del nostro percorso, alla sfida finale, quasi al boss di fine gioco. La prossima volta i ragazzi dovranno presentare tutto quanto fatto. Siamo proprio ansiosi di vedere come lo step finale verrà affrontato da ognuno di loro. Le scelte di chi presenterà, come, gli strumenti ed, ultimo ma non per importanza, come gestiranno i tempi.
Siamo arrivati al sesto incontro con i ragazzi. La quarantena non ci lascia tregua ma noi siamo più tenaci e non molliamo di certo! Ormai l’incontro su Microsoft Teams è consolidato e sarà il fatto che è ora di colazione o che ci troviamo tutti “insieme” ma a casa, insomma, ci si sente quasi in famiglia.
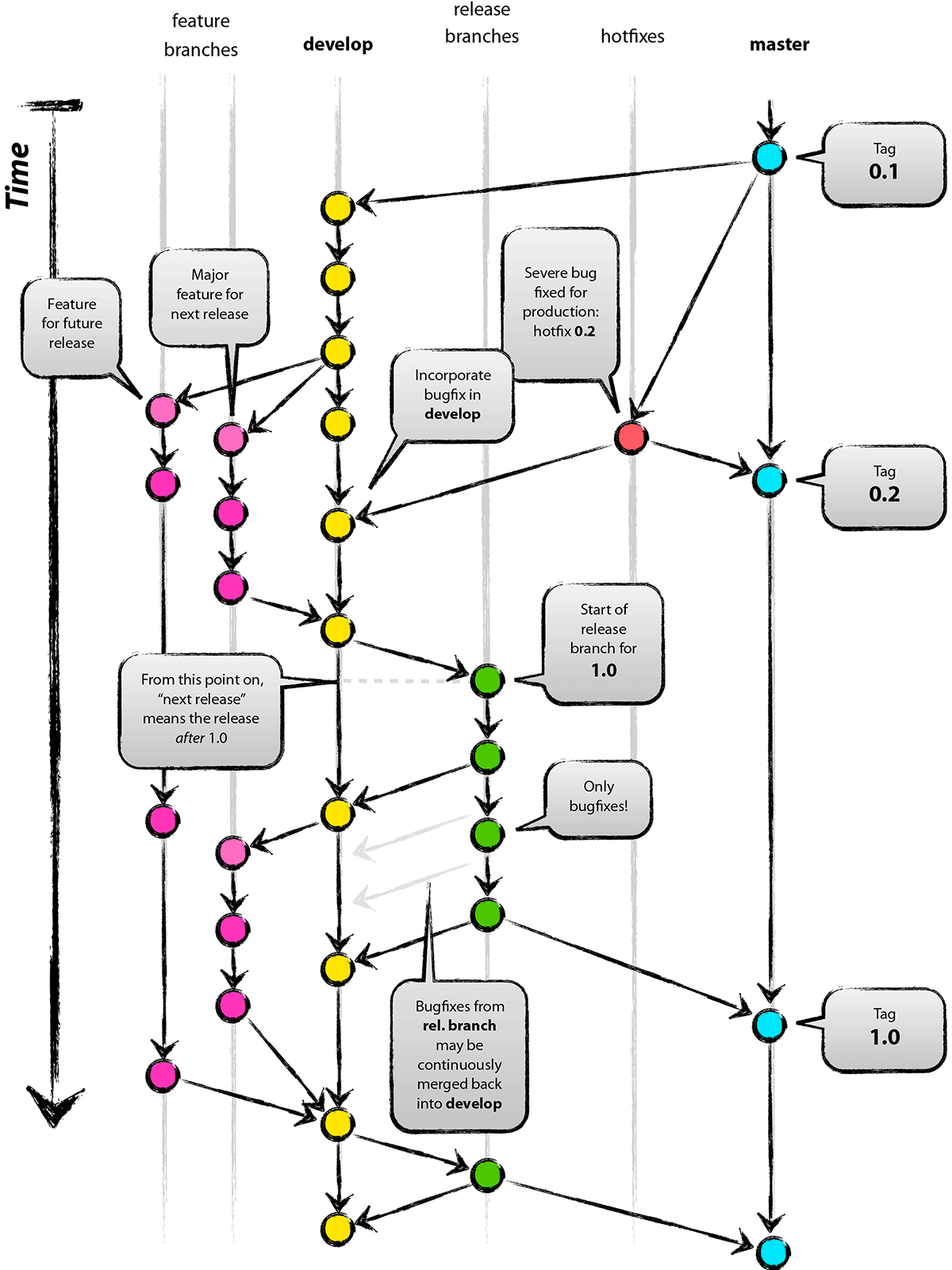
Ma bando alle ciance, perché oggi tocca al branching su Git, pratica molto utile e consigliata nell’utilizzo quotidiano, ma allo stesso tempo complessa e insidiosa.
[…] il branching risulta essenziale per poter testare l’efficienza di implementazioni differenti o per realizzare dei proof-of-concept in corso d’opera.
Chi sviluppa conosce bene il tema, essendo vita di tutti i giorni. Tuttavia, in certi frangenti, è necessario chiedere aiuto alla documentazione o a chi può esserci di aiuto. Per questo motivo Pier-Paolo, con tanta pazienza, ha preferito mantenere un livello di applicazione piuttosto semplice, portando esempi pratici tratti dalla nostra esperienza lavorativa aziendale, per meglio dimostrare ai ragazzi la reale utilità di questo strumento.
Il branching, il nostro miglior alleato
I vantaggi del branching non si limitano al fatto di poter sviluppare funzionalità differenti in parallelo o da sviluppatori differenti. Infatti, risulta essenziale per poter testare l’efficienza di implementazioni differenti o per realizzare dei proof-of-concept in corso d’opera. Pier-Paolo ha inoltre evidenziato l’eventualità, in realtà fin troppo frequente, del verificarsi di conflitti nel codice al momento del merge dei vari branch su quello principale di sviluppo. E cosa ha deciso di far provare ai ragazzi?
gitflow, esempio di branching su git
Reazioni dei ragazzi ai primi conflitti
Il caso più semplice che abbiamo sottoposto ai ragazzi si verifica quando due o più sviluppatori modificano il medesimo file in punti differenti. Ma siamo arrivati al caso più critico, quello di un file modificato nello stesso punto. Abbiamo seguito insieme i passi necessari per risolvere i conflitti tramite SmartGit e la condivisione dello schermo (vedi smart learning).
La lezione è stata davvero impegnativa, ma i ragazzi sembrano aver seguito con attenzione e compreso bene, reagendo con prontezza grazie anche alle indicazioni degli strumenti ai quali sono abituati.
Durante la prossima lezione vedremo molto probabilmente qualche risultato tangibile in termini di prodotto. Di certo parleremo di documentazione funzionale destinata all’utente finale, aspetto spesso tralasciato in favore della realizzazione tecnica del software.
Continuate a seguirci, l’esperimento delle lezioni online sta procedendo a gonfie vele e ormai manca poco a vederne i risultati finali.
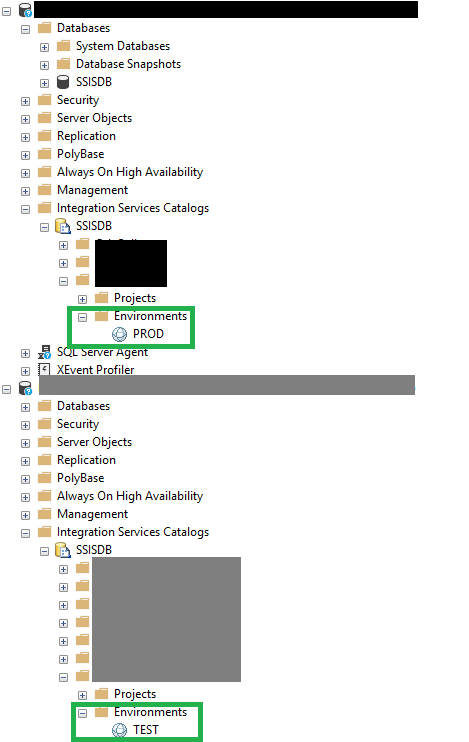
In a previous post, we’ve described the “from scratch” approach on the development side. When everything works well there, a push (or check-in) triggers the build engine. We must deal with two SQL Server instances (SSIS Servers hereafter), with an environment for each of them:
The build pipeline
The SSIS Servers keep Vertica‘s test and production mappings as well as test and production connection strings for the SQL Server databases. So we need the right variable mapping for all the scenarios, but this is not in the scope of the post, we will speak about it in the next posts. Anyways, here is how the build pipeline works:
Our build process
You may notice that the task “Copy vertica deploy scripts” is disabled. Well, to be honest, right now we’re waiting for the target integration environment.
Build process explained
In the beginning, the build server gets the source files from the repository and creates the target artifacts folder with a Powershell script. This will be the path from which we will push the artifacts to the release pipeline.
The build server generates the .ispac file for the SQL Server Integration Services packages using the dedicated task. The copy tasks will be executed:
As you can see, we’ve got a set of utilities and transformation tools, that will be executed in the release pipeline as well as the environment script. This one contains the SSISDB variables mapping and the SSIS Project configurations statements. Misc files, .sql files for environments and the .ispac file will be copied to the target artifacts folder.
The tasks above copy our template of the .nuspec file to generate the NuGet file (NuGet pack step). This is what we get using NuGet:
Then, we’re ready to publish the files to the release pipeline. We will see how the release pipeline works in the next posts.
Ehm… you miss Vertica
Yes, you’re right. But, it’ll be just a copy of .sql files to the artifacts folder. We will see how the release manager will execute them, so…
Ed eccoci alla seconda lezione completamente online! L’impatto è stato molto meno forte; la volta scorsa abbiamo avuto un po’ di tensione causata dalla mancanza di esperienza, mentre stavolta la lezione è filata via senza intoppi (tolto qualche problema tecnico iniziale, prontamente risolto dal gentilissimo personale della scuola). È un buon segno. Nonostante tutto, è possibile (addirittura auspicabile?) una forma di educazione online, che nulla ha da invidiare alle classiche lezioni frontali, eccetto il rapporto umano, ovviamente.
Comunque, venendo ai temi della lezione, anche questa volta lo scopo è stato quello di “far parlare” i ragazzi: è piuttosto evidente che la maggior parte di loro non è abituata a interagire più del necessario (per carità, alla loro età…), però una delle cose che vorremmo gli restasse da questa esperienza è proprio quella di imparare i comportamenti tipici del team. In un ambiente lavorativo, dove la comunicazione e il lavoro di squadra sono centrali, infatti, possono fare la differenza.
Pier-Paolo ha iniziato la lezione riprendendo le fila di quella precedente e ha cercato di far comprendere meglio agli studenti la differenza fra un approccio waterfall (a cascata) e uno ad iterazioni, tipico invece dello sviluppo agile, che in questo periodo è addirittura indicato nei decreti ministeriali. Quello che si è notato è la tendenza da parte dei ragazzi di procedere in un modo un po’ “tutto o niente”, poco organizzato nel tempo, per quanto riguarda le implementazioni; in ambito lavorativo ciò non consente di portare un reale valore tangibile al cliente. Infatti, non gli viene fornita una versione coerente del lavorato e non gli si da visibilità dei progressi nel software fino a fine sviluppo. I ragazzi dovrebbero cominciare a lavorare più a “storie”, realizzando parti del loro software, magari piccole, ma funzionanti e “visibili” findai primi momenti (agile e iterazioni).
Le impressioni positive che già avevamo rilevato sono poi state confermate: la modalità totalmente online con cui si svolge la lezione è vincente. Anche questa volta il professore ha chiesto di mostrare l’avanzamento dei progetti ed è evidente che i ragazzi si stiano abituando al backlog e alla creazione e presa in carico dei task. Manca ancora il poter vedere i progetti funzionanti, ma siamo confidenti nelle prossime lezioni.
La lezione è terminata con una breve dimostrazione dell’integrazione fra le push su GitHub e Azure DevOps (impostate la volta precedente). La prossima settimana vedremo se tutto questo avrà portato i voluti risultati. Speriamo anche di poter iniziare a parlare di branching style, ma questo è un argomento ostico anche per i lavoratori, quindi non sarà semplice.
Bene, continuiamo così nonostante le difficoltà che ci stanno mettendo a dura prova. Alla prossima lezione!
Vista l’emergenza in corso, è passato un po’ di tempo dall’ultimo aggiornamento e di cose ne sono successe: poco dopo l’ultima lezione, infatti, il Coronavirus ha iniziato a diffondersi e sono state prese contromisure sempre più restrittive per arginare il fenomeno. Si è arrivati infine al divieto per tutti i cittadini di uscire di casa, a meno di emergenze e necessità lavorative.
[…] un’occasione per sperimentare una nuova condizione, per mettere alla prova gli strumenti che usiamo tutti i giorni sul lavoro.
Da parte nostra, si può dire che abbiamo avuto “fortuna”, sia perché la nostra attività quotidiana (la programmazione) può essere eseguita anche fuori dall’ufficio via telelavoro, sia perché avevamo già predisposto anche prima del virus gli strumenti per metterla in pratica, per cui siamo stati fra i primi ad adottare l’utilizzo dello smart working che ci permette di lavorare da casa. Engage IT Services nasce in telelavoro, da tre persone che non avevano soldi per un ufficio, e oggi, grazie alla filosofia descritta qui, possiamo dire “ragazzi, da lunedì si lavora da casa” senza nessun problema di sorta. Un problema a dire il vero c’è, il caffè insieme, quello ci manca davvero!
Ma cos’è successo nelle scuole? In quella seguita da noi, in particolare, il professore non si è voluto perdere d’animo e, dopo un paio di lezioni sospese per precauzione, ci ha chiesto disponibilità per tenere una delle nostre lezioni in modalità di meeting online con gli studenti: ovviamente abbiamo accettato con entusiasmo, sia perché ci sarebbe dispiaciuto lasciare indietro i ragazzi sugli argomenti che avevamo preparato, sia perché era un’occasione per sperimentare una nuova condizione, per mettere alla prova gli strumenti che usiamo tutti i giorni sul lavoro.
Ed eccoci qui, tutti pronti da casa con Microsoft Teams configurato e avviato in attesa di essere invitati alla “riunione” della classe. SPOILER: la lezione è andata alla grande e ha guadagnato molto dal fatto di essersi svolta online invece che di persona, e nel seguito vedremo il perché.
Partiamo dallo svolgimento della lezione: cominciamo col dire che questa ha avuto un tono molto da “review”; è stato chiesto ai ragazzi, uno per gruppo, di illustrare ciò che avevano fatto in queste settimane (non crediate che se ne siano stati con le mani in mano, anzi) evidenziando principalmente quale fosse stata l’organizzazione del team negli sviluppi. Dopo ogni presentazione, abbiamo quindi riesaminato le board per capire se i nuovi PBI fossero stati inseriti correttamente e abbiamo fornito consigli su come migliorarne la stesura.
Particolare attenzione è stata posta ancora una volta sulla disciplina necessaria ad adottare una serie di processi. Sebbene in un ambiente scolastico essi possano risultare “pesanti”, a lungo termine non possono che incrementare consapevolezza ed efficienza nel modo di lavorare.
Tutto questo è avvenutotramite schermo condiviso e ciò ha permesso una partecipazione forse più diretta rispetto ad una lezione frontale in cui i ragazzi spesso non riescono a condividere quanto implementato o a interagire direttamente su quanto mostra il professore. Nonostante molti ragazzi non disponessero di un computer e si fossero collegati con smartphone o tablet, l’impressione è stata che la lezione si trasformasse in qualcosa di più personale. Le distanze “fisiche”, già inevitabili in classe e in questo frangente anche più estese, si sono praticamente annullate. E questo ha portato molta più partecipazione.
[…] essere reattivi al cambiamento sia un processo fondamentale di ognuno di noi, azienda o individuo.
La lezione è terminata con la richiesta di collegare i repository GitHub dei ragazzi alla nostra board Azure, per poter mostrare loro la prossima volta l’integrazione fra i due mondi: abbiamo quindi mostrato la procedura per la creazione dei Personal Access Token, toccando così anche l’argomento sicurezza nella gestione dei repository.
L’aspetto su cui Pier-Paolo insisterà nella prossima lezione è quello della creazione di valore aggiunto ad ogni iterazione: sembra infatti essere presente un po’ di “dispersione” negli sviluppi. Anche il professor Memoli ha richiesto, dal canto suo, che i ragazzi mostrassero qualcosa di funzionante e tangibile per evidenziare tale problematica.
Il primo esperimento si può quindi dire concluso con successo e non vediamo l’ora di proseguire con la prossima lezione per avere conferma delle nostre impressioni! Una cosa che vogliamo sottolineare è che in questo periodo di emergenza, non solo chi sfrutta i nostri servizi cambia. Cambiamo anche noi e questo non fa altro che incrementare la consapevolezza di come essere reattivi al cambiamento sia un processo fondamentale di ognuno di noi, azienda o individio. Questi ragazzi ci hanno dato un insegnamento non piccolo. Si può fare!
Si sente spesso dire che la scuola non ha tutti gli strumenti per poter fronteggiare formazione in remoto. In generale, il mondo della formazione scolastica è considerato talvolta un po’ arretrato. In realtà, l’istituto che stiamo seguendo, sia con progetti paralleli, sia come alternanza scuola-lavoro è ed è sempre stata all’avanguardia. Forse sono un po’ di parte, visto che si tratta della scuola in cui ho studiato, ma credo che meriti una degna menzione.
Ancor prima che io potessi contattare i professori per tentare il progetto in remoto, ho ricevuto una telefonata dal professor Christian Memoli che, riassumendo, chiedeva: “abbiamo tutto per fare da remoto, abbiamo Teams, abbiamo strumenti di video conferenza, è un problema per la tua azienda? Noi stiamo già facendo didattica a distanza.”. Che cosa posso dire? Prima di tutto, che l’IISS Gadda di Fornovo Taro è pronto, veramente. Poi, nel mondo del lavoro di cui noi informatici siamo parte, non spesso il telelavoro è ben visto, mentre una scuola dimostra un sentimento responsabile e proattivo.
Attenzione, non fraintendetemi, per la nostra azienda, TUTTI e sottolineo TUTTI i clienti e i fornitori hanno condiviso, chiesto e supportato il lavoro da remoto. Però conosco casi in cui, seppure possibile come strada da percorrere, il telelavoro non è ancora ben visto. Per fortuna la nostra realtà aziendale non ha questo tipo di conflitto, anzi! Consapevolezza e responsabilità vanno per la maggiore, unitamente al rispetto per la salute di tutti.
A partire da mercoledì, seguiremo una serie di incontri (purtroppo ancora fino a data da destinarsi) utilizzando Microsoft Teams (strumento già utilizzato dalla scuola regolarmente), connettendosi in Azure DevOps Services e sfruttando GitHub come già indicato nei post precedenti della serie. Il tutto da remoto! Sento che questo progetto, già interessante, non farà altro che diventarlo ancora di più. Dimostreremo le possibilità dell’informatica, terremo comunque i ragazzi interessati e chiuderemo il progetto, senza farci fermare dallo spazio fisico.