Mai come negli ultimi tempi, ho iniziato a fare analisi riguardanti l’on boarding dei nuovi assunti in azienda. Per noi la parte di ricerca del personale e il conseguente percorso iniziale con il team sono argomenti di massimo interesse. Del resto, il futuro è basato per la maggior parte su come ci si muove fin dai primi istanti.
Devo essere sincero, fin dalla sua nascita, l’azienda è stata fatta sempre e solo di tecnici e, in quanto tali, abbiamo sempre dato molto peso all’approfondimento delle tecnologie e delle pratiche legate al mondo dello sviluppo.
Poi qualcosa è cambiato. Abbiamo iniziato a ragionare in termini davvero people-first, anche per necessità di crescita. Già dopo un paio di anni abbiamo iniziato ad assumere al di fuori di quel contesto costruito praticamente su amicizia e conoscenze comuni. Di recente, poi, è arrivata una crescita del personale del doppio delle unità e da qui la necessità di affrontarelne la selezione ancora più in maniera oculata e precisa.
In ogni punto del ciclo di vita aziendale abbiamo qualcosa definito in wiki.
[…] oggi le wiki sono piuttosto complete anche se, probabilmente per un tempo limitato
Insomma, l’on boarding diventa un momento in cui investire, non solo per chi deve crescere in quell’istante, ma anche per chi deve preparare materiale per il futuro e per chi arriverà. Per noi, il “dove” in cui mettere il sapere è la wiki di Azure DevOps. Una delle nostre principali alleate, tutti i giorni.
Come utilizziamo la wiki
In ogni punto del ciclo di vita aziendale abbiamo qualcosa definito in wiki. L’on boarding é il primo capitolo di uno strumento che accompagnerà i membri dei nostri team ogni giorno. L’elenco delle cose da avere, il nostro welcome kit, è anch’esso su di una pagina wiki che illustra a chi è stato assunto gli strumenti e gli accessi disponibili. Da lì, un “get started” fornisce gli step per creare la propria workstation e avviare la nostra piattaforma, come gira effettivamente in produzione, solo più effimera.
Di certo, ora è semplice a dirsi, l’implementazione degli strumenti descritti, come gli script di automazione del provisioning della sandbox o del database su container, ha richiesto anni di osservazioni e miglioramento continuo. Per cui solo oggi le wiki sono piuttosto complete anche se, probabilmente per un tempo limitato. Tuttavia, quando si entra nel mood del “continuous” è tutto all’ordine del giorno.
Per usufruire di questo vantaggio però, è necessario avere nel DNA aziendale concetti di cambiamento e miglioramento continui
La documentazione dei processi
Documentare un processo aziendale tramite una wiki può essere visto come un costo, soprattutto quando l’azienda cambia non poco spesso. Ma la wiki in sé non può definirsi tale, anche perché si trasforma subito in un ritorno dell’investimento non appena consumata dalle persone che lavorano in azienda. Per usufruire di questo vantaggio però, è necessario avere nel DNA aziendale concetti di cambiamento e miglioramento continui. Se si prevede nelle proprie pipeline di sviluppo una parte di wiki (attenzione, documentazione non di progetto semplicemente, ma di processo e di tutto quanto è il sapere dell’azienda) esso poi, col tempo, entra nel DNA di tutti e anche chi diventa il tutore di chi inizia il percorso con noi passa il modus operandi ai propri adepti, rendendo, di fatto, il procedimento inarrestabile. Uno di quelli di cui non si può più fare a meno.
Un modus operandi alla portata di tutte le realtà
Credo che questa abitudine sia assolutamente alla portata di tutti ma, allo stesso tempo, applicabile dipendentemente da vari fattori.
Partire daccapo ed ereditare situazioni
Per chi ha la fortuna di iniziare qualcosa daccapo, come un progetto o una migrazione culturale, direi che basta iniziare col piede giusto. Chi eredita, invece, situazioni Legacy, non orientate ad un approccio iterativo come vale per DevOps o Agile, potrebbe avere non pochi problemi. Perché comunque si parla di mindset.
Per ottenere risultati da un procedimento di questo tipo è necessario prima abbracciare la cultura del cambiamento e del miglioramento continuo. Se non si è pronti a ciò, il rischio è quello di avere una bella wiki all’inizio, derivante da un progetto dedicato alla sua creazione, e poi trovarsi a definirla obsoleta in poco tempo. Qualcosa di cui fare manutenzione che fa solo perdere tempo e, di conseguenza, che fa perdere fiducia nello strumento, nel suo utilizzo e nella metodologia.
Innestare tutto quanto nel processo di selezione del personale
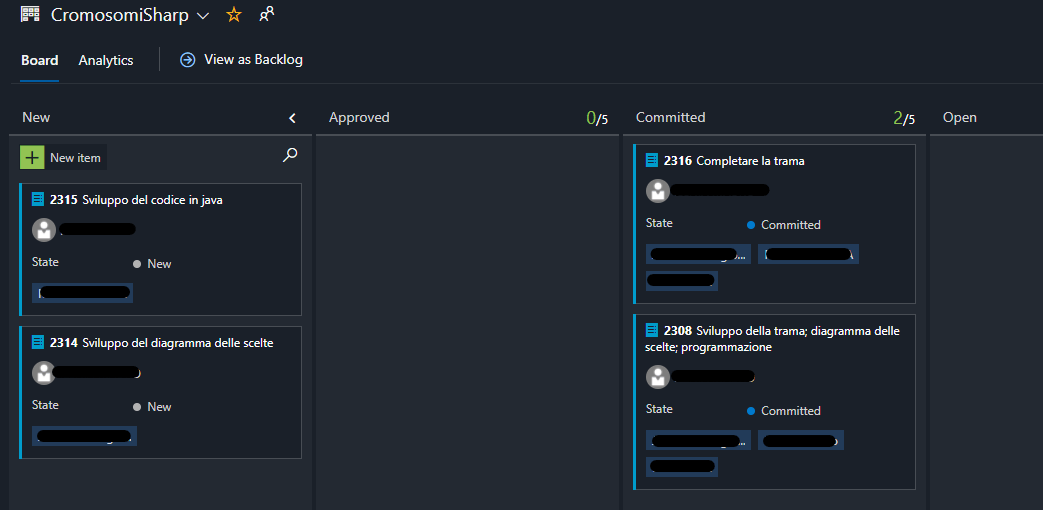
Avendo una wiki per come fare le interviste e i colloqui, sia per la parte attitudinale sia per la parte tecnica, risulta tutto molto naturale. Gli stati della pratica di assunzione sono su di una board di Azure DevOps, in cui viene seguito il procedimento completo, dalla ricerca, ai colloqui, all’assunzione, alle licenze e fino alla burocrazia. A supporto di questo, gli step indicati sulla wiki alla sezione “hiring”, dedicata ovviamente all parte di assunzione. Come è facile capire, gli strumenti sono a supporto di una radicata cultura orientata all’organizzazione, nell’ottica di ridurre gli sprechi e le perdite di tempo, portando, di fatto, valore aggiunto tramite ogni cosa che si fa. O almeno ci si prova.
Crescita professionale e futuro della persona
Anche per questo abbiamo, guarda caso, wiki che descrivono come la persona verrà accompagnata e come pian piano, o meglio, nei tempi che il “tutore” decide essere consoni, crescerà. Proprio adesso stiamo lavorando ad una sezione in cui si gestisce parte del mantenimento del rapporto, la crescita professionale in generale e le posizioni aperte in azienda, tramite un organigramma che mostra cosa manca e cosa abbiamo. Personalmente, tengo allineate wiki private su progetti dedicati nelle quali vi sono i punti salienti dei nostri one-to-one trimestrali. Come viene fatto un incontro one-to-one è ovviamente descritto in wiki, tanto per cambiare.
Conclusioni e suggerimenti
Come per ogni cosa che metta in relazione uno strumento con un modo di procedere più culturale, è fondamentale che si parta dalla cultura, appunto, e che lo strumento sia un efficace supporto. Consiglio di cercare strumenti per fare wiki che siano vestiti sui vostri processi, in modo da evitare inutili sprechi di tempo. Considerate che ci sono voluti anni nella nostra realtà, che praticamente è nata su pilastri DevOps e Agili.
Inoltre, la wiki non deve essere un trattato approfondito di tutto lo scibile aziendale. Preferite la formula “bullet point”, quindi liste, piuttosto che scrivere paragrafi infiniti. E preferite che tutti possano proattivamente metterci le mani, in fondo è l’approccio giusto.
Legato anche al punto precedente, una wiki non dovrebbe essere una perdita di tempo. Se passate più tempo a gestirla significa che qualcosa non è corretto. Più cose non salienti scriverete, più cose potenzialmente cambieranno e quindi dovranno essere verificate e modificate. Va dosato il rapporto costi/benefici.
Infine, una volta entrati nel mood, valutare anche di usare non solo le wiki per documentare processi, ma anche quelle di codice, per sfruttare i repository al meglio, come vale per i repo GitHub. Con Azure DevOps questo è praticamente naturale.
Insomma, le wiki possono essere viste come un potentissimo strumento a supporto dell’organizzazione aziendale, anche per dare un’immagine della propria realtà in totale trasparenza e in accordo con il lavoro di tutti i membri dei team e dei dipartimenti. Una vera alleata.