Siamo ancora in pandemia. Abbiamo una buona percentuale di vaccinati, ma ancora dobbiamo avere a che fare con relazioni in remoto. Lo stesso vale per il nostro amato e inarrestabile progetto: Agile@School. Siamo arrivati al sesto anno consecutivo e questa volta, con un’idea orientata al mondo videoludico.

Non a caso l’immagine di copertina richiama uno dei giochi punta e clicca più conosciuti di tutti i tempi, col quale ho perso ore e ore nei pomeriggi della mia adolescenza: The Secret Of Monkey Island tm.
Il cosa
“Facciamo un gioco, sì, produciamolo. Pur semplice che sia, ma creiamo qualcosa di nostro”. Questa è la missione che i ragazzi hanno quest’anno. Il tipo è quello della saga di “Lupo Solitario” (Lone Wolf), un famoso libro game di qualche tempo fa. Abbiamo deciso di far fare agli studenti un piccolo motore basato su “decisioni –> conseguenze”, un grafo in cui una storia viene sviluppata e diventa la strada di un personaggio con una semplice caratteristica, l’energia vitale.
Il come
Decidano i ragazzi. C++? Java? Angular? Javascript? Python? Quello che vogliono. Ci sono solo tre vincoli:
- La storia deve essere derivata dal programma di una materia, anche per coinvolgere altri professori.
- La storia deve essere un’avventura semplice, per arrivare ad un lavorato funzionante in un solo mese.
- Le scelte possibili devono essere al massimo 3, con altrettante conseguenze: avanti senza subire danni, avanti subendo danni, fine del gioco prematura (fine energia vitale improvvisa).
Gli strumenti
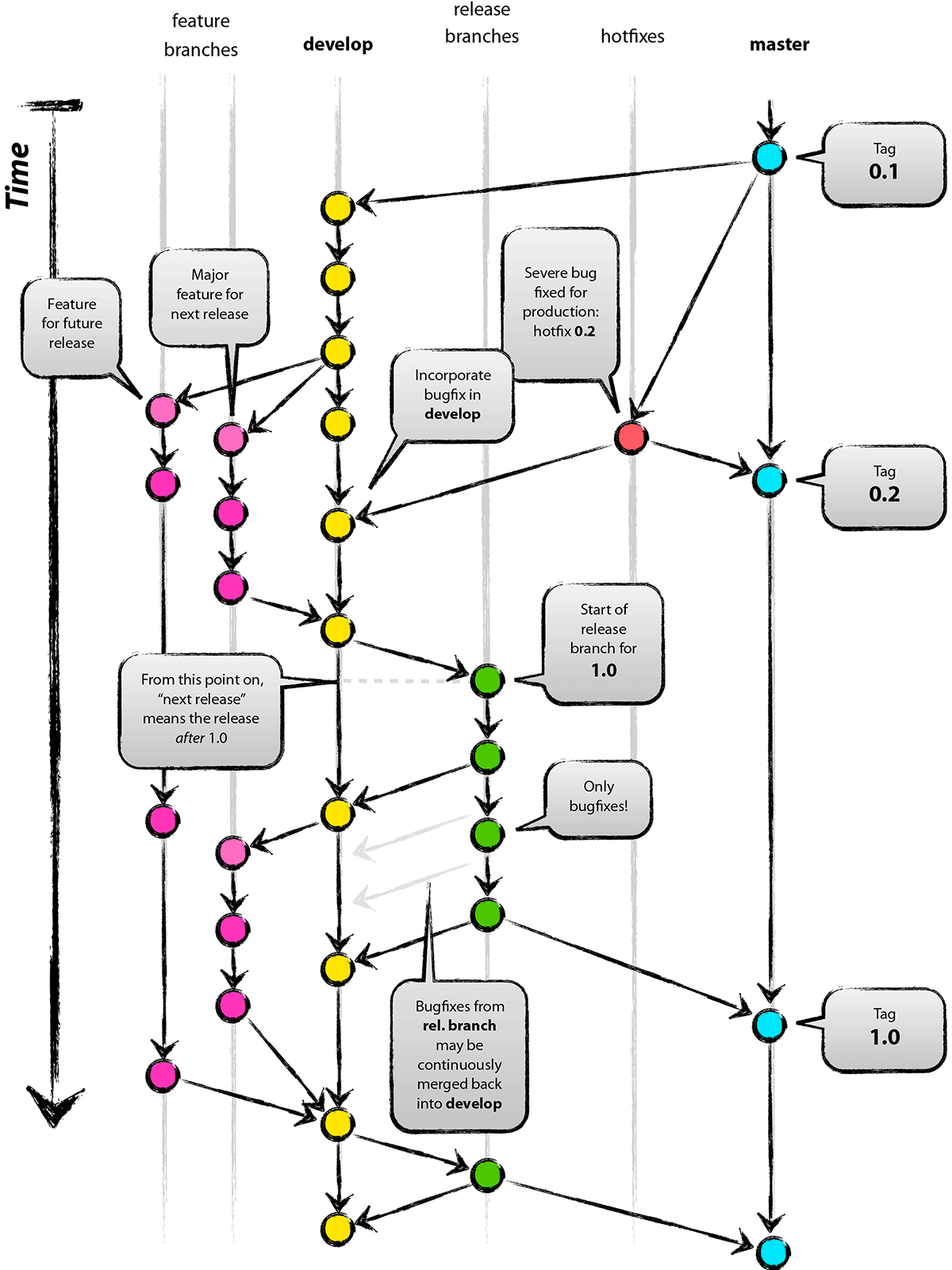
La gestione del progetto sarà in Agile, e con SCRUM. Per implementare la parte di gestione, abbiamo creato 4 team con altrettanti backlog, solo Product Backlog Item e Task. Utilizzeremo git come source control manager e, in generale, ogni editor di codice legato alla tecnologia scelta dai ragazzi.
Infine, le presentazioni prevedono un piccolo video, una serie di mock grafici nell’arco del progetto e una bella demo del software alla fine di tutto.
I team
I ragazzi hanno già scelto i nomi dei team:
- FISHER: “perché abbiamo tutti un soprannome comune che richiama tale nome”
- CROMOSOMI#: “un joke per il linguaggio C++”
- MONKETECK: “due parole, e la seconda per esprimere senso di tecnologia”
- GENTS&LADY.PY: “gentlemen e una ragazza, in python, o almeno ci proviamo”
Ogni team è di 5/6 persone e le figure che abbiamo identificato sono:
- PO: product owner, uno per team, che si riferirà a me per lo stato dei lavori (non dimentichiamo che io sono il cliente del gioco).
- Marketing: figura che curerà la presentazione.
- Tech lead: figura che seguirà le implementazioni anche a livello decisionale, riferimento di Pier-Paolo, che anche quest’anno sarà il loro appoggio tecnico.
- Developer: chiunque partecipi al progetto e sviluppa parti del gioco
Insomma, ci sarà da divertirsi. Aspettatevi qualche post nel breve, perché i ragazzi hanno già iniziato a buttarsi a capofitto nel progetto. La passione sembra averli abbracciati.
Stay Tuned!